在SQL Server 中插入一条数据使用Insert语句,但是如果想要批量插入一堆数据的话,循环使用Insert不仅效率低,而且会导致SQL一系统性能问题。下面介绍SQL Server支持的两种批量数据插入方法:Bulk和表值参数(Table-Valued Parameters),高效插入数据。
新建数据库:
--Create DataBase create database BulkTestDB; go use BulkTestDB; go --Create Table Create table BulkTestTable( Id int primary key, UserName nvarchar(32), Pwd varchar(16)) go
一.传统的INSERT方式
先看下传统的INSERT方式:一条一条的插入(性能消耗越来越大,速度越来越慢)
//使用简单的Insert方法一条条插入 [慢]
#region [ simpleInsert ]
static void simpleInsert()
{
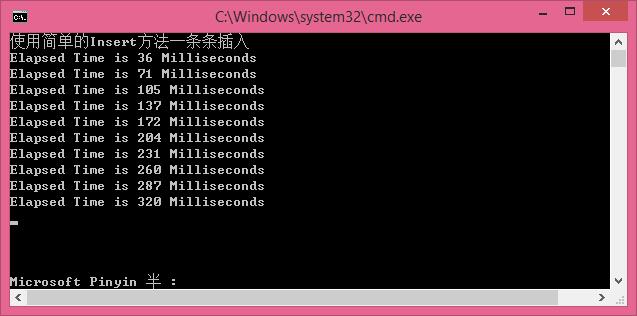
Console.WriteLine("使用简单的Insert方法一条条插入");
Stopwatch sw = new Stopwatch();
SqlConnection sqlconn = new SqlConnection("server=.;database=BulkTestDB;user=sa;password=123456;");
SqlCommand sqlcmd = new SqlCommand();
sqlcmd.CommandText = string.Format("insert into BulkTestTable(Id,UserName,Pwd)values(@p0,@p1,@p2)");
sqlcmd.Parameters.Add("@p0", SqlDbType.Int);
sqlcmd.Parameters.Add("@p1", SqlDbType.NVarChar);
sqlcmd.Parameters.Add("@p2", SqlDbType.NVarChar);
sqlcmd.CommandType = CommandType.Text;
sqlcmd.Connection = sqlconn;
sqlconn.Open();
try
{
//循环插入1000条数据,每次插入100条,插入10次。
for (int multiply = 0; multiply < 10; multiply++)
{
for (int count = multiply * 100; count < (multiply + 1) * 100; count++)
{
sqlcmd.Parameters["@p0"].Value = count;
sqlcmd.Parameters["@p1"].Value = string.Format("User-{0}", count * multiply);
sqlcmd.Parameters["@p2"].Value = string.Format("Pwd-{0}", count * multiply);
sw.Start();
sqlcmd.ExecuteNonQuery();
sw.Stop();
}
//每插入10万条数据后,显示此次插入所用时间
Console.WriteLine(string.Format("Elapsed Time is {0} Milliseconds", sw.ElapsedMilliseconds));
}
Console.ReadKey();
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
}
}
#endregion
循环插入1000条数据,每次插入100条,插入10次,效率是越来越慢。
二.较快速的Bulk插入方式:
使用使用Bulk插入[ 较快 ]
//使用Bulk插入的情况 [ 较快 ]
#region [ 使用Bulk插入的情况 ]
static void BulkToDB(DataTable dt)
{
Stopwatch sw = new Stopwatch();
SqlConnection sqlconn = new SqlConnection("server=.;database=BulkTestDB;user=sa;password=123456;");
SqlBulkCopy bulkCopy = new SqlBulkCopy(sqlconn);
bulkCopy.DestinationTableName = "BulkTestTable";
bulkCopy.BatchSize = dt.Rows.Count;
try
{
sqlconn.Open();
if (dt != null && dt.Rows.Count != 0)
{
bulkCopy.WriteToServer(dt);
}
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
}
finally
{
sqlconn.Close();
if (bulkCopy != null)
{
bulkCopy.Close();
}
}
}
static DataTable GetTableSchema()
{
DataTable dt = new DataTable();
dt.Columns.AddRange(new DataColumn[] {
new DataColumn("Id",typeof(int)),
new DataColumn("UserName",typeof(string)),
new DataColumn("Pwd",typeof(string))
});
return dt;
}
static void BulkInsert()
{
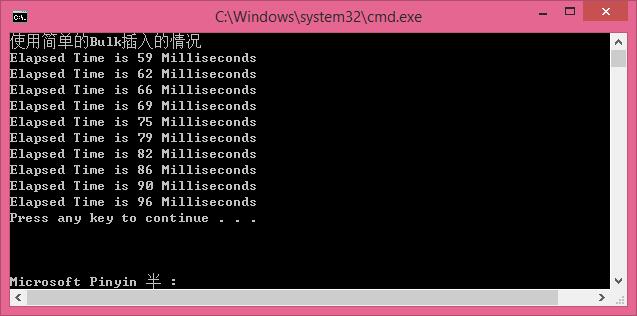
Console.WriteLine("使用简单的Bulk插入的情况");
Stopwatch sw = new Stopwatch();
for (int multiply = 0; multiply < 10; multiply++)
{
DataTable dt = GetTableSchema();
for (int count = multiply * 100; count < (multiply + 1) * 100; count++)
{
DataRow r = dt.NewRow();
r[0] = count;
r[1] = string.Format("User-{0}", count * multiply);
r[2] = string.Format("Pwd-{0}", count * multiply);
dt.Rows.Add(r);
}
sw.Start();
BulkToDB(dt);
sw.Stop();
Console.WriteLine(string.Format("Elapsed Time is {0} Milliseconds", sw.ElapsedMilliseconds));
}
}
#endregion
循环插入1000条数据,每次插入100条,插入10次,效率快了很多。
三.使用简称TVPs插入数据
打开sqlserrver,执行以下脚本:
--Create Table Valued CREATE TYPE BulkUdt AS TABLE (Id int, UserName nvarchar(32), Pwd varchar(16))
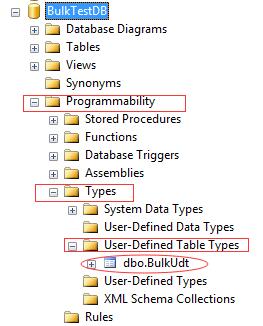
成功后在数据库中发现多了BulkUdt的缓存表。
使用简称TVPs插入数据
//使用简称TVPs插入数据 [最快]
#region [ 使用简称TVPs插入数据 ]
static void TbaleValuedToDB(DataTable dt)
{
Stopwatch sw = new Stopwatch();
SqlConnection sqlconn = new SqlConnection("server=.;database=BulkTestDB;user=sa;password=123456;");
const string TSqlStatement =
"insert into BulkTestTable (Id,UserName,Pwd)" +
" SELECT nc.Id, nc.UserName,nc.Pwd" +
" FROM @NewBulkTestTvp AS nc";
SqlCommand cmd = new SqlCommand(TSqlStatement, sqlconn);
SqlParameter catParam = cmd.Parameters.AddWithValue("@NewBulkTestTvp", dt);
catParam.SqlDbType = SqlDbType.Structured;
catParam.TypeName = "dbo.BulkUdt";
try
{
sqlconn.Open();
if (dt != null && dt.Rows.Count != 0)
{
cmd.ExecuteNonQuery();
}
}
catch (Exception ex)
{
Console.WriteLine("error>" + ex.Message);
}
finally
{
sqlconn.Close();
}
}
static void TVPsInsert()
{
Console.WriteLine("使用简称TVPs插入数据");
Stopwatch sw = new Stopwatch();
for (int multiply = 0; multiply < 10; multiply++)
{
DataTable dt = GetTableSchema();
for (int count = multiply * 100; count < (multiply + 1) * 100; count++)
{
DataRow r = dt.NewRow();
r[0] = count;
r[1] = string.Format("User-{0}", count * multiply);
r[2] = string.Format("Pwd-{0}", count * multiply);
dt.Rows.Add(r);
}
sw.Start();
TbaleValuedToDB(dt);
sw.Stop();
Console.WriteLine(string.Format("Elapsed Time is {0} Milliseconds", sw.ElapsedMilliseconds));
}
Console.ReadLine();
}
#endregion
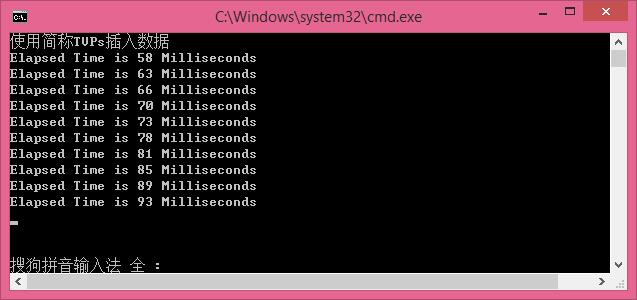
循环插入1000条数据,每次插入100条,插入10次,效率是越来越慢,后面测试,将每次插入的数据量增大,会更大的体现TPVS插入的效率。
到此这篇关于SQL Server批量插入数据案例详解的文章就介绍到这了,更多相关SQL Server批量插入数据内容请搜索NICE源码以前的文章或继续浏览下面的相关文章希望大家以后多多支持NICE源码!