今天由于工作需要,需要把数据把列根据指定的内容拆分数据
其中一条数据实例
select id , XXXX FROM BIZ_PAPER where id =’4af210ec675927fa016772bf7dd025b0′

拆分方法:
select t3.id ,t3.XXXX as XXXX from (
select A.id , B.XXXX from (
SELECT id, XXXX = CONVERT(xml,'<root><v>' + REPLACE(XXXX , ',', '</v><v>') + '</v></root>') FROM BIZ_PAPER) A
outer apply(
SELECT XXXX = N.v.value('.', 'varchar(100)') FROM A.XXXX .nodes('/root/v') N(v)) B) t3 where t3.id ='4af210ec675927fa016772bf7dd025b0'
结果
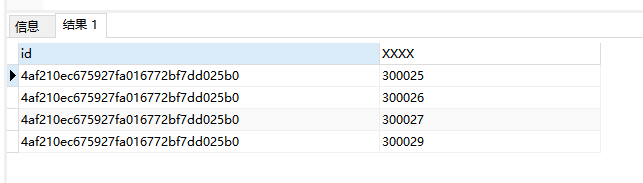
在自己研究这行代码之后,做出如下讲解,如果有错误的地方还请指教
SELECT id, XXXX = CONVERT(xml,'<root><v>' + REPLACE(XXXX , ',', '</v><v>') + '</v></root>') FROM BIZ_PAPER
这一行的重点在于CONVERT,XML是指类型,xml 数据类型实例拆分为关系数据,则 nodes() 方法非常有用,至于XML类型的数据,我后面进行补充
REPLACE 指按照 ‘ , ‘ 进行替换,并且按照指定的内容进行拼接
最后的结果为

outer apply
这个就是表的关联,就像是left join ,但是没有on 作为关联条件,所以通过拆分之后多出来的数据就是通过这个进行关联后产生的
SELECT XXXX = N.v.value('.', 'varchar(100)') FROM A.XXXX .nodes('/root/v') N(v)
N.v.value(‘.’,’varchar(100)’),N是表,别名,v是列,value函数是读取标签之间的值,对于这个列子,读取的为<v>和</v>中间的值;这个可以去了解 xml类型的常用的三个方法 :value()、nodes()、exist()
value的第一个参数是一个字符串文字,从 XML 实例内部检索数据。 XQuery 必须最多返回一个值。 否则,将返回错误;
value的第二个参数是指将查询结果转化为何种类型的数据。
此处,’.’表示当前目录,即<v>目录,另外’..’表示上级目录,’/’表示根目录,这个跟Linux是一样的
总的来说,这个语句的重点在于xml类型的使用和outer apply的使用,其他的都很好理解。这个就是我自己理解后的讲解,部分位置我自己也还没有理解透
总结
到此这篇关于Sql Server数据把列根据指定内容拆分数据的文章就介绍到这了,更多相关SqlServer数据列根据内容拆分数据内容请搜索NICE源码以前的文章或继续浏览下面的相关文章希望大家以后多多支持NICE源码!







