本文实例讲述了MYSQL数据库表结构优化方法。分享给大家供大家参考,具体如下:
选择合适的数据类型
1、使用可以存下你的数据的最小的数据类型
2、使用简单的数据类型。Int要比varchar类型在mysql处理上简单
3、尽可能的使用not null定义字段
4、尽量少用text类型,非用不可时最好考虑分表
使用int来存储日期时间,利用FROM_UNIXTIME()【将int类型时间戳转换成日期时间格式】,UNIX_TIMESTAMP()【将日期时间格式转换成int类型】两个函数进行转换
使用bigint来存储IP地址,利用INET_ATON()【将IP格式转换成int】,INET_NTOA()【将int格式转换成正常IP格式】两个函数进行转换
表的范式化和反范式化
范式化是指数据库设计的规范,目前的范式化一般指第三设计范式,也就是要求数据表中不存在非关键字段对任意候选关键字段
的传递函数依赖则符合第三范式。
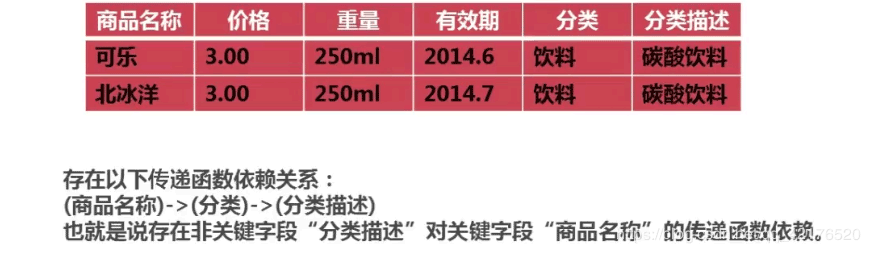
不符合第三范式要求的表存在下列问题:
1、数据冗余:(分类,分类描述)对于每一个商品都会进行记录
2、数据的插入/更新/删除异常
范式化操作:
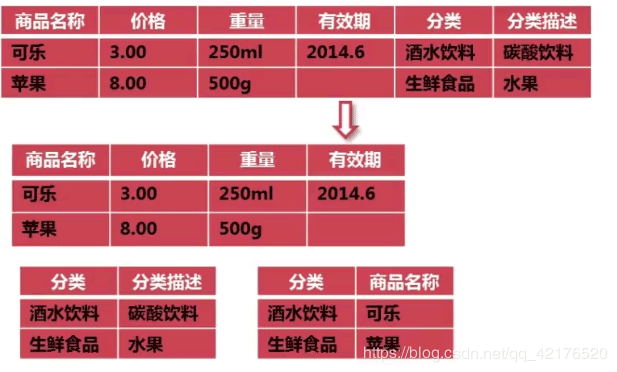
反范式化是指为了查询效率和考虑把原本符合第三范式的表适当的增加冗余,以达到优化查询效率的目的,反范式化是一种以空间来换取时间的操作。
例:


对表进行反范式化

反范式化查询订单信息:

表的垂直拆分
垂直拆分就是把原来 很多列的表拆分成多个表,这就解决了表的宽度问题。通常垂直拆分可以按以下原则进行:
1、把不常用的字段单独存放到一个表中。
2、把大字段独立存放到一个表中。
3、把经常一起使用的字段放到一起。
水平拆分
表的水平拆分是为了解决单表的数据量过大问题,水平拆分的表每个表的结构都是完全一致的

常用的水平拆分方法:
1、对customer_id进行hash运算,如果要拆分成5个表则使用mod(custoneer_id,5)取出0-4个值
2、针对不同的hashID把数据存到不同的表中
更多关于MySQL相关内容感兴趣的读者可查看本站专题










