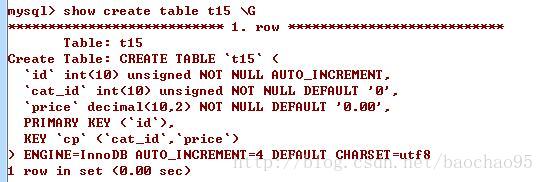
本文实例讲述了mysql重复索引与冗余索引。分享给大家供大家参考,具体如下:
重复索引:表示一个列或者顺序相同的几个列上建立的多个索引。
冗余索引:两个索引所覆盖的列重叠
冗余索引在一些特殊的场景下使用到了索引覆盖,所以比较快。
场景
比如文章与标签表
+——+——-+——+
| id | artid | tag |
+——+——-+——+
| 1 | 1 | PHP |
| 2 | 1 | Linux |
| 3 | 2 | MySQl |
| 4 | 2 | Oracle |
+——+——-+——+
在实际使用中, 有2种查询
- artid—查询文章的—tag
- tag—查询文章的 —artid
SQL语句:
select tag from t11 where artid=2; select artid from t11 where tag='PHP';
我们可以建立冗余索引,来达到索引覆盖的情况,这样的查询效率会比较高。
1、建立一个文章标签表
这个表中有两个索引,一个是at,一个是ta,两个索引都用到了artid和tag两个字段。
CREATE TABLE `t16` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `artid` int(10) unsigned NOT NULL DEFAULT '0', `tag` char(20) NOT NULL DEFAULT '', PRIMARY KEY (`id`), KEY `at` (`artid`,`tag`), KEY `ta` (`tag`,`artid`) ) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8
2、测试两条SQL语句
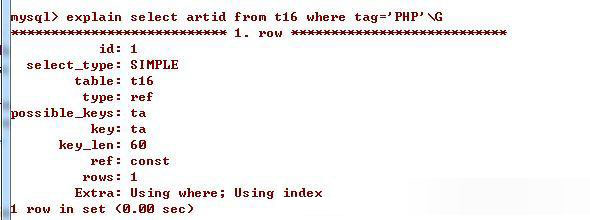
select artid from t11 where tag='PHP';
这条语句的查询分析中的Extra有Using index,表示此处用到了索引覆盖,使用索引覆盖后就不需要回行查询数据,这样的查询效率比较高。
select tag from t11 where artid = 1;
这条语句的查询分析中的Extra有Using index,表示此处用到了索引覆盖,使用索引覆盖后就不需要回行查询数据,这样的查询效率比较高。

关于索引覆盖的详细内容可以查看前面一篇文章:索引覆盖
更多关于MySQL相关内容感兴趣的读者可查看本站专题