背景介绍
复制,就是对数据的完整拷贝,说到为什么要复制,首先能想到的是怕数据意外丢失,使得用户蒙受损失。
当完成了数据复制之后,会发现它的优势不止这一点,假如一台机器宕机了,可以启用备份在另一台机器的数据。毕竟宕机的概率很小,闲暇时间还可以让备份机器分担主机器的流量压力。除此之外,当要升级数据库版本时,可以在不停止用户服务的情况下优先升级备用机器,待观测其可用稳定时再将主数据库升级。
但是,也不能总让DBA手动拷贝来完成复制,万一在DBA蹲坑的时候宕机了,在蹲坑期间产生的数据由于没有及时备份,会导致备用数据库的数据缺失,所以还是要设计一套可以自动复制的机制。

设计复制机制
我们暂定被复制的数据库为主库,粘贴出来的为从库,要实现主库到从库的复制,看起来非常简单,只需一个计划任务,定时将主库数据文件复制一份,并传输到从库所在服务器。
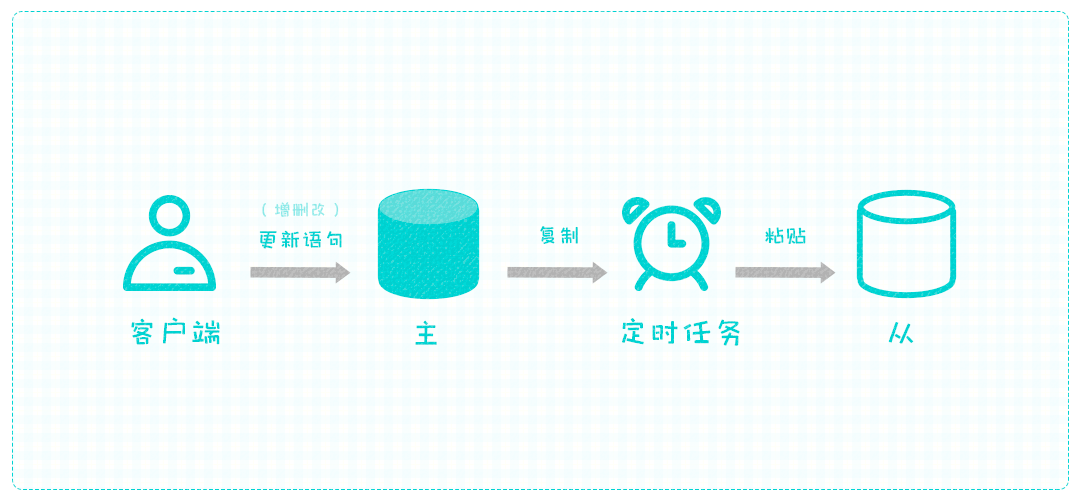
但毕竟定时任务不是实时的,万一主库在上次复制的十分钟后发生了故障,被激活的从库用的是最近一次复制的数据,所以会缺失十分钟的数据,后果不堪设想。

还是要实时复制,那可以这样,主库将每次执行完的语句实时发给从库,让从库马上执行,就能保证两边数据一致了。
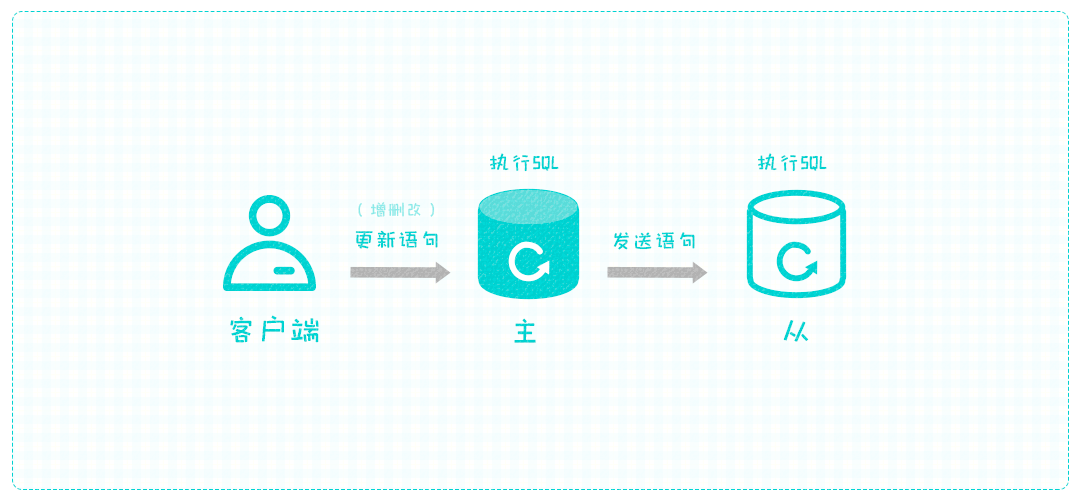
不太好的是,主库是实时发送数据给从库的,需要等从库执行完毕才能处理下一条语句,严重占用了主库的执行时间,如果从库过多,主库就废了。

还得改成异步才能节省主库的时间,可以将主库执行完的语句存到文件里,让从库来取,这样主库就不用等待从库了。既然是写到文件,速度是很快的,主库完全可以在执行前就将语句写到文件中,达到更高的同步效率。
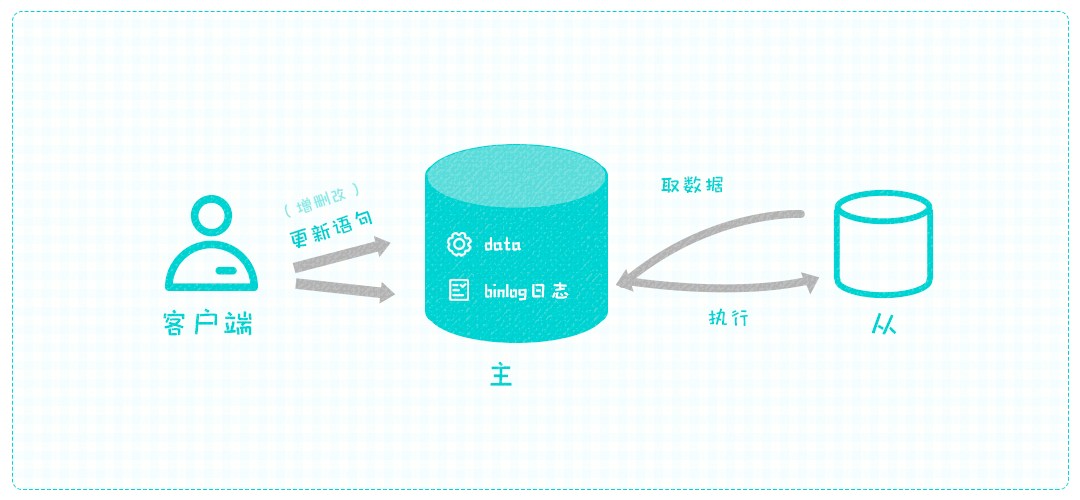
上述有些问题,从库无法做到跑去主库取数据,只能起一个线程先与主库建立连接,并向主库索要数据,然后主库也起一个线程读取文件内容,并推给从库线程,从库收到语句后就可以马上执行了。
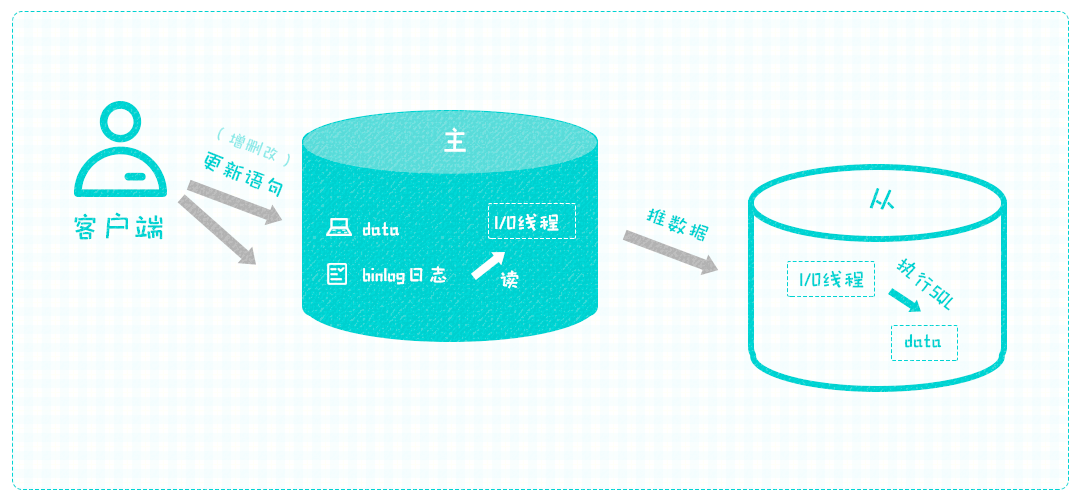
这样效率还是很低,主库的线程要等从库收到语句并执行完毕才能推下一条,如果有多个从库,主库就要开启多个线程长期与各个从库保持通信,占用主库服务器资源,不如从库也创建个文件临时保存主库发来的语句,先存起来再慢慢执行,主库压力小了,从库也放心。
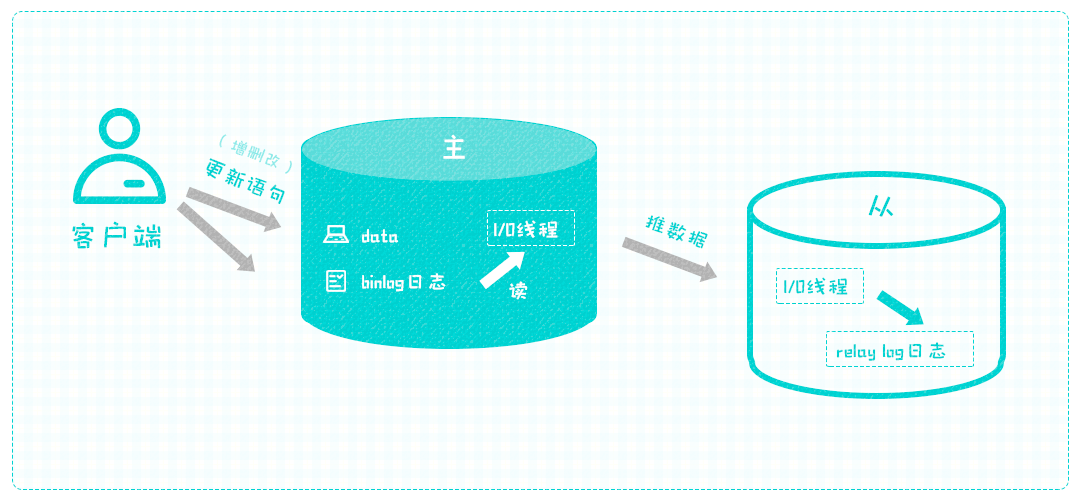
现在从库有了自己的文件做中继,就不用着急了,从库可以再起一个线程,慢慢执行中继文件中的语句,执行完毕之后原文件没有价值了,就可以清理掉,免得占用服务器资源。
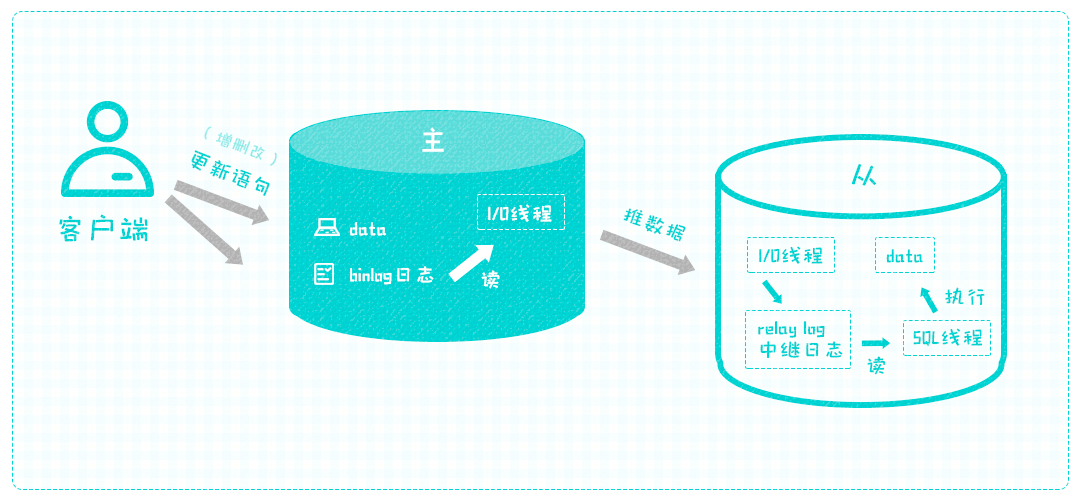
到目前为止,最基本的复制机制就设计完了,这种由主库到从库的复制方式就是典型的主从架构,在此基础上可以进行演化,比如从库有很多,主库要为每个从库推送数据,主库的压力会随之增大,又因为主库的职责不仅仅是同步数据,还要忙着读写数据,所以同步数据的事可以找人代替,比如在主库与从库之间再建立一个主库,新建立的主库唯一的职责就是同步数据给从库,这样真正的主库就只需要推送一次数据给新建的主库,其余时间就可以安心读写数据了。
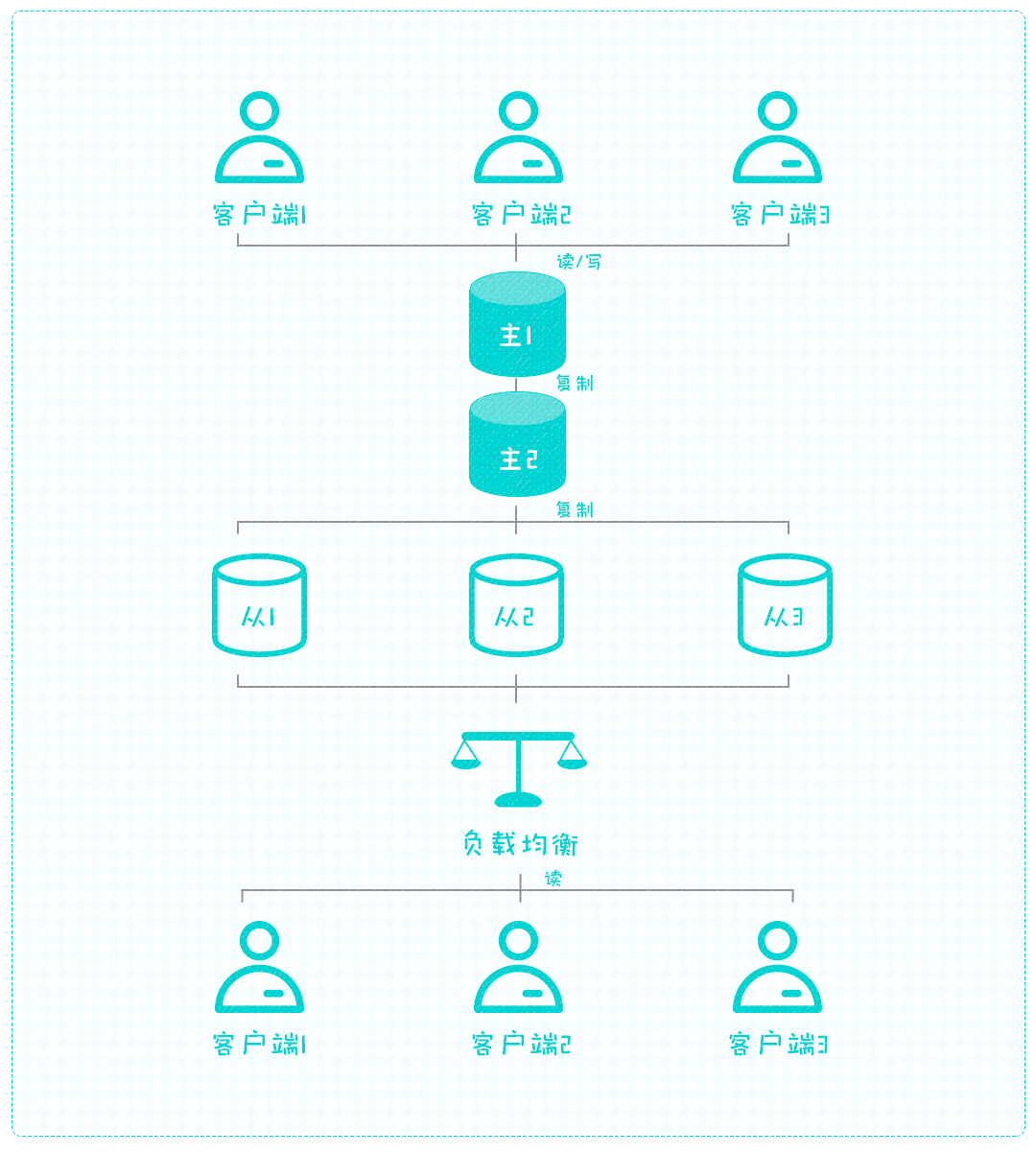
这种演化而来的复制模式叫做多级复制架构,本文到此结束,上述就是三种复制架构中的其中两种,除此之外还有一个“主主”架构,在这里就不再多说了,感兴趣的可以自行了解或关注后续的文章。
以上就是全部关于MySQL复制机制的知识点内容,感谢大家对NICE源码的支持。