在数据库表里,我们有时候会保存了很多重复的数据,这些重复的数据浪费资源,我们要将其删除掉,应该怎么处理呢?下面来看一下。
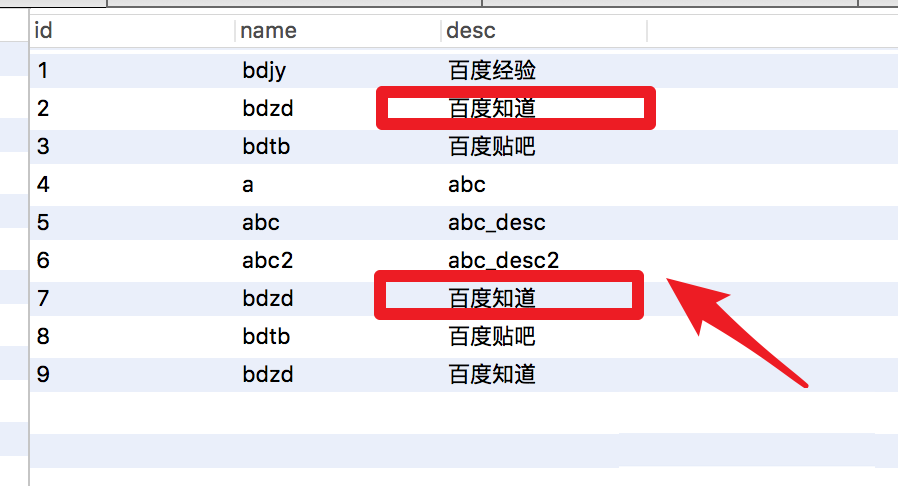
先看下我们的表数据,有一些数据是重复的。
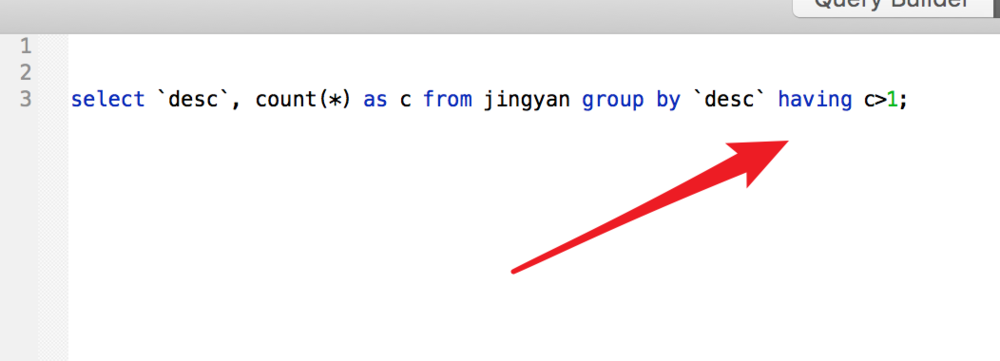
要查找重复数据,我们可以使用mysql里的having语句,如图。
执行这个语句后,我们可以看到现在的结果里显示的就是表中重复数据的字段。
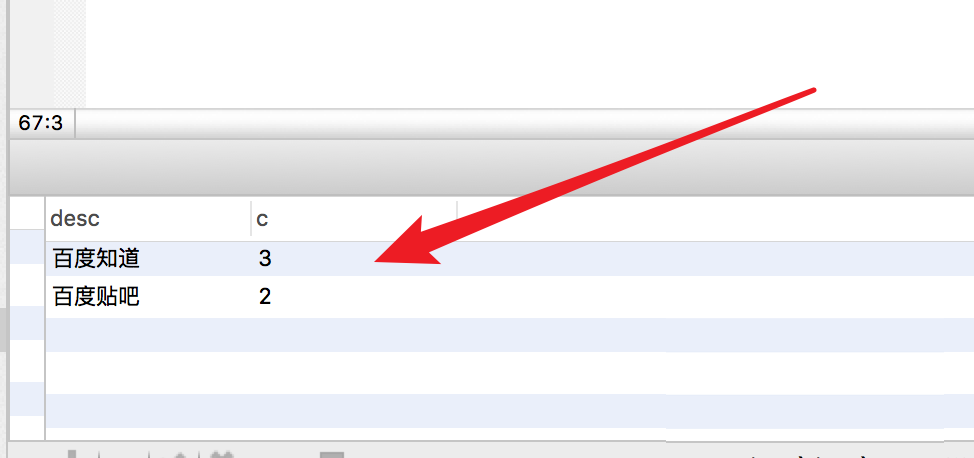
要删除这些重复的数据,我们找出这些数据的ID,在select语句里,添加id字段,使用max函数,可以得到重复数据最后面的id。
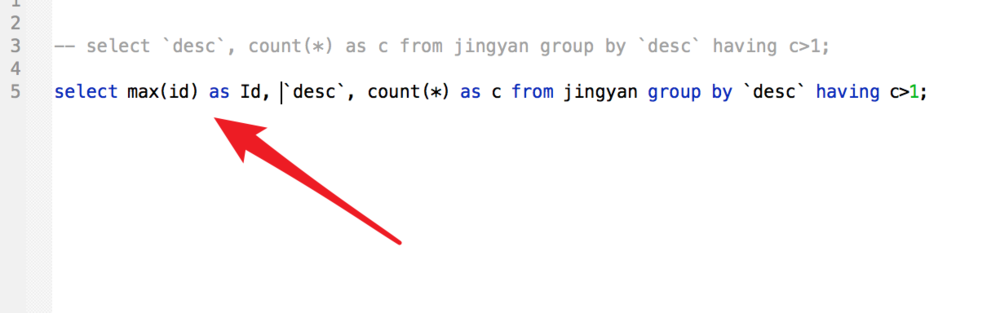
执行结果如图,得到重复数据的id为8和9。
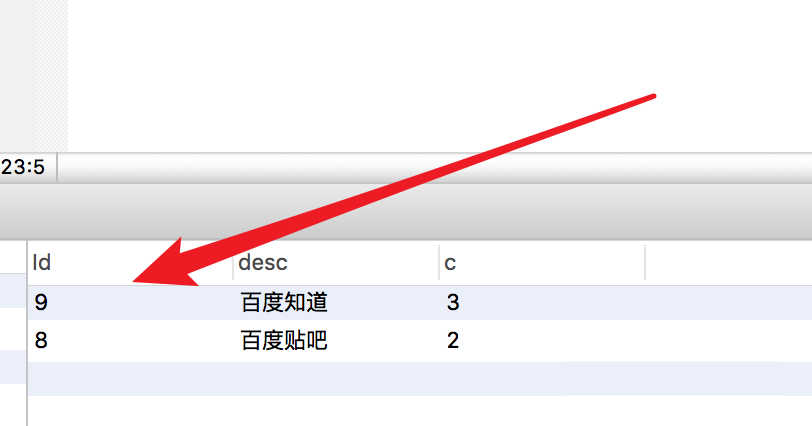
这样我们就可以使用delete语句来删除这二个id的数据了。
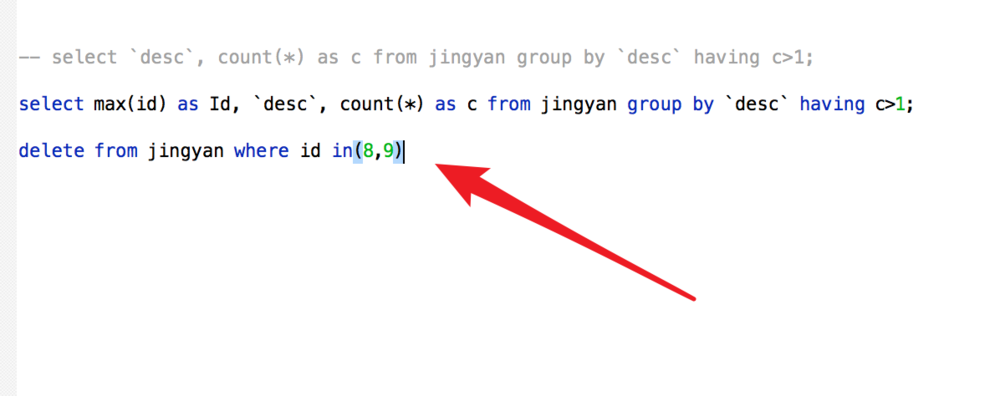
但如果有很多重复的数据,不想一个一个的写这些id怎么办?
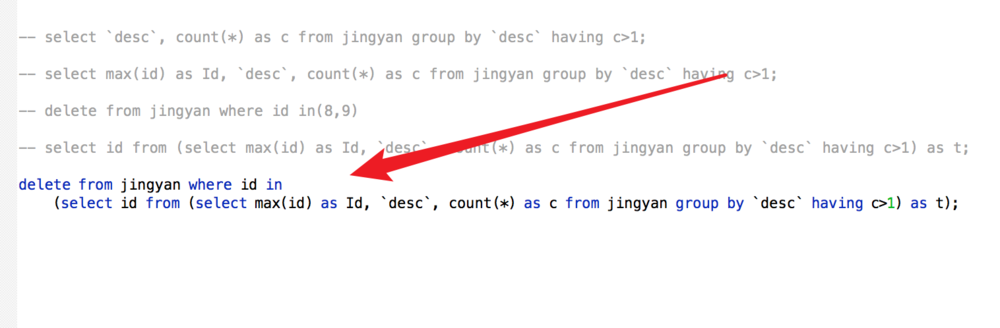
添加一个子查询,只把id字段查询出来,如图。
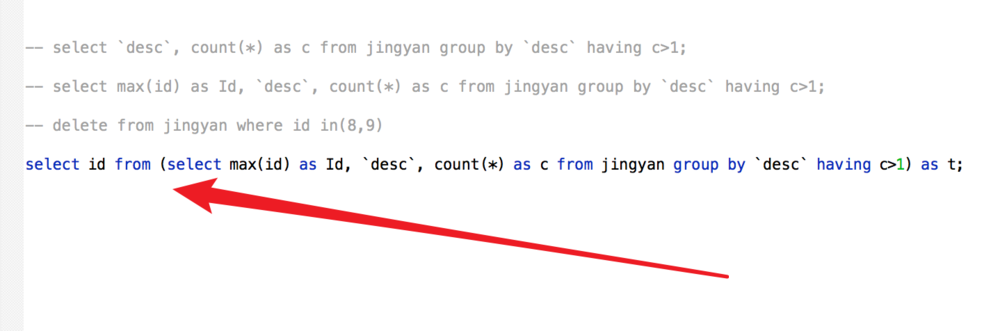
然后在外边添加一个delete语句就行了,详细代码如图。
要注意的是,如果重复数据的行有三行或以上的,我们需要执行这个语句多次才行,因为执行一次只会删除每组重复数据中的一条。