多路搜索树
- 完全二叉树高度:O(log2N),其中2为对数
- 完全M路搜索树的高度:O(logmN),其中M为对数,树每层的节点数
- M路搜索树主要用于解决数据量大无法全部加载到内存的数据存储。通过增加每层节点的个数和在每个节点存放更多的数据来在一层中存放更多的数据,从而降低树的高度,在数据查找时减少磁盘访问次数。
- 所以每层的节点数和每个节点包含的关键字越多,则树的高度越矮。但是在每个节点确定数据就越慢,但是B树关注的是磁盘性能瓶颈,所以在单个节点搜索数据的开销可以忽略。
B树
B树是一种M路搜索树,B树主要用于解决M路搜索树的不平衡导致树的高度变高,跟二叉树退化为链表导致性能问题一样。B树通过对每层的节点进行控制、调整,如节点分离,节点合并,一层满时向上分裂父节点来增加新的层等操作来来保证该M路搜索树的平衡。具体规则如下:
- 根节点的儿子树个数在2到M之间,其他非叶子节点的儿子树个数在M/2和M之间。如果儿子树个数因为分裂超过了M则此时需要向上递归分裂父节点,当找到一个不需要再分裂的父节点则停止分裂。该分裂过程直到根节点,如果需要分裂根节点,则会产生两个根,故需要创建一个新的根来将这两个根作为儿子节点,此时树的高度会增加1。
- 每个非叶子节点的关键字的值从左到右依次变大,第i个关键字代表子树i+1中的最小关键字;(其中对于根节点来说i在1到(2到M)之间,其他非叶子节点则是1到(M/2到M)之间);
- B树的所有数据项都存放到叶子节点,非叶子节点不存放数据,非叶子节点只存放用于指示搜索方向的关键字,即索引。这样有利于将更多的非叶子节点加载到内存中,方便进行数据查找;
- 所有叶子节点都在相同的深度并且每个叶子节点包含L/2到L项数据。
M和L的大小选择
- M为B树的阶数或者说是路数
- L为每个叶子节点最多存放的数据项个数
- 在B树中,每个节点都是一个磁盘区块,所以需要根据磁盘区块的大小来决定M和L。
磁盘区块大小与M的计算
- 每个非叶子节点存放了关键字和指向儿子树的指针,具体数量为:M阶的B树,每个非叶子节点存放了M-1个关键字和M个指向儿子树的指针,故加入每个关键字的大小为8字节(如Java的long类型就是8字节),每个指针为4字节,则M阶B树的每个非一叶子节点需要:8 * (M-1) + 4 * M = 12M – 8个字节。
- 如果规定每个非叶子节点(磁盘区块)占用内存不超过8K,即8192,则M最大为683,即683*12-8=8192。
叶子节点数据项个数L
- 假如每个数据项大小也是256字节,则由于磁盘区块大小为8K,即8192个字节,而每个叶子节点可以存放L/2到L个数据项,所以每个叶子节点最多存放:8192/256=32个数据项,即L的大小为32。
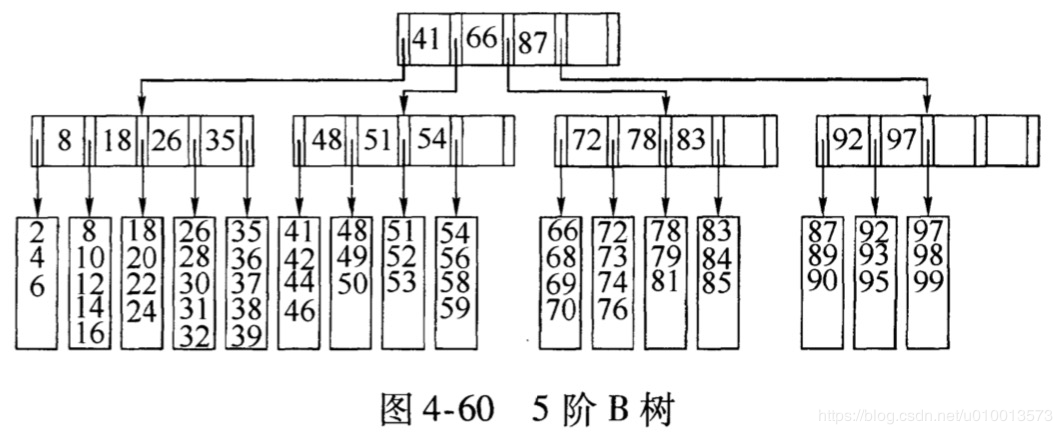
- 一棵5阶的B树的结构如下,即M和L等于5:其中每个非叶子节点包含最多M-1=5-1=4个关键字,包含M,即5个指向子树指针。L等于5,则每个叶子节点最多存放5个数据项。
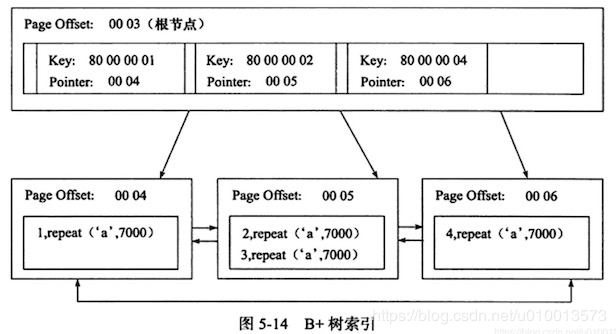
B+树
B+树结构跟B树基本一致,唯一的区别是B+树的叶子节点之间通过指针相连形成一个链表,故便于遍历所有的叶子节点,即获取所有或者搜索关键字某一范围的所有数据项。MySQL的InnoDB存储引擎就是会用B+树作为索引实现。
以上所述是小编给大家介绍的多路搜索树B树、B+树详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对NICE源码网站的支持!