概述
在关系数据库中,索引是一种单独的、物理的对数据库表中一列或多列的值进行排序的一种存储结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。
mysql中支持hash和btree索引。innodb和myisam只支持btree索引,而memory和heap存储引擎可以支持hash和btree索引
1、查看当前索引使用情况
我们可以通过下面语句查询当前索引使用情况:
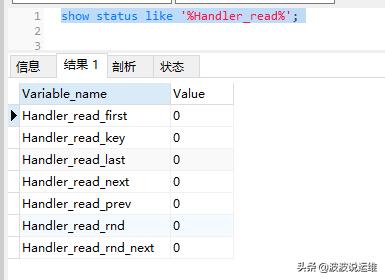
- Handler_read_first 代表读取索引头的次数,如果这个值很高,说明全索引扫描很多。
- Handler_read_key代表一个索引被使用的次数,如果我们新增加一个索引,可以查看Handler_read_key是否有增加,如果有增加,说明sql用到索引。
- Handler_read_next 代表读取索引的下列,一般发生range scan。
- Handler_read_prev 代表读取索引的上列,一般发生在ORDER BY … DESC。
- Handler_read_rnd 代表在固定位置读取行,如果这个值很高,说明对大量结果集进行了排序、进行了全表扫描、关联查询没有用到合适的KEY。
- Handler_read_rnd_next 代表进行了很多表扫描,查询性能低下。
其实比较多应用场景是当索引正在工作,Handler_read_key的值将很高,这个值代表了一个行将索引值读的次数,很低的值表明增加索引得到的性能改善不高,因为索引并不经常使用。
Handler_read_rnd_next 的值高则意味着查询运行低效,并且应该建立索引补救。这个值的含义是在数据文件中读下一行的请求数。如果正进行大量的表 扫描,Handler_read_rnd_next的值较高,则通常说明表索引不正确或写入的查询没有利用索引
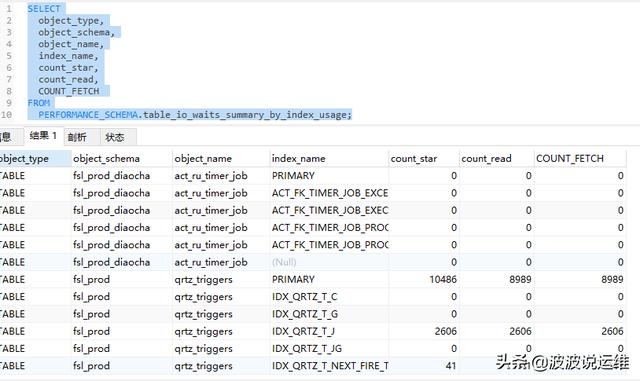
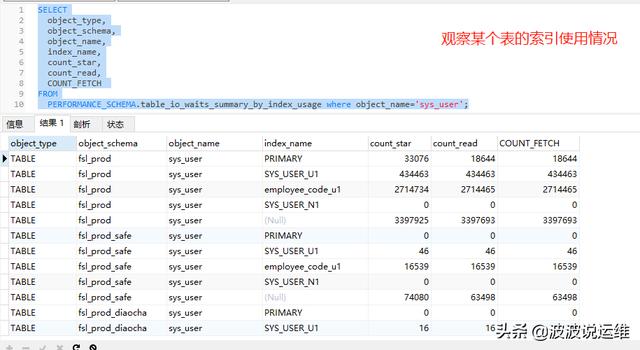
2、查看索引是否被使用到
SELECT object_type, object_schema, object_name, index_name, count_star, count_read, COUNT_FETCH FROM PERFORMANCE_SCHEMA.table_io_waits_summary_by_index_usage;
如果read,fetch的次数都为0的话,就是没有被使用过的。
3、查看使用了哪些索引
explain相关sql,查看type表示查询用到了那种索引类型
+-----+-------+-------+-----+--------+-------+---------+-------+ | ALL | index | range | ref | eq_ref | const | system | NULL | +-----+-------+-------+-----+--------+-------+---------+-------+
从最好到最差依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
- system 表中只有一条记录,一般来说只在系统表里出现。
- const 表示通过一次索引查询就查询到了,一般对应索引列为primarykey 或者unique where语句中 指定 一个常量,因为只匹配一行数据,MYSQL能把这个查询优化为一个常量,所以非常快。
- eq_ref 唯一性索引扫描。此类型通常出现在多表的 join 查询,对于每一个从前面的表连接的对应列,当前表的对应列具有唯一性索引,最多只有一行数据与之匹配。
- ref 非唯一性索引扫描。同上,但当前表的对应列不具有唯一性索引,可能有多行数据匹配。此类型通常出现在多表的 join 查询, 针对于非唯一或非主键索引, 或者是使用了 最左前缀 规则索引的查询.
- range 索引的范围查询。查询索引关键字某个范围的值。
- index 全文索引扫描。与all基本相同,扫描了全文,但查询的字段被索引包含,故不需要读取表中数据,只需要读取索引树中的字段。
- all 全文扫描。未使用索引,效率最低。
顺便提几个优化注意点:
1、优化insert语句:
1)尽量采用 insert into test values(),(),(),()…
2)如果从不同客户插入多行,能通过使用insert delayed语句得到更高的速度,delayed含义是让insert语句马上执行,其实数据都被放在内存队列中个,并没有真正写入磁盘,这比每条语句分别插入快的多;low_priority刚好相反,在所有其他用户对表的读写完后才进行插入。
3)将索引文件和数据文件分在不同磁盘上存放(利用建表语句)
4)如果进行批量插入,可以增加bulk_insert_buffer_size变量值方法来提高速度,但是只对MyISAM表使用
5)当从一个文本文件装载一个表时,使用load data file,通常比使用insert快20倍
2、优化group by语句:
默认情况下,mysql会对所有group by字段进行排序,这与order by类似。如果查询包括group by但用户想要避免排序结果的消耗,则可以指定order by null禁止排序。
3、优化order by语句:
某些情况下,mysql可以使用一个索引满足order by字句,因而不需要额外的排序。where条件和order by使用相同的索引,并且order by的顺序和索引的顺序相同,并且order by的字段都是升序或者降序。
4、优化嵌套查询:
mysql4.1开始支持子查询,但是某些情况下,子查询可以被更有效率的join替代,尤其是join的被动表待带有索引的时候,原因是mysql不需要再内存中创建临时表来完成这个逻辑上需要两个步骤的查询工作。
最后提一个点:
一个表最多16个索引,最大索引长度256字节,索引一般不明显影响插入性能(大量小数据例外),因为建立索引的时间开销是O(1)或者O(logN)。不过太多索引也是不好的,毕竟更新之类的操作都需要去维护索引。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对NICE源码的支持。