本文实例讲述了mysql学习笔记之完整的select语句用法。分享给大家供大家参考,具体如下:
本文内容:
- 完整语法
- 去重选项
- 字段别名
- 数据源
- where
- group by
- having
- order by
- limit
首发日期:2018-04-11
完整语法:
先给一下完整的语法,后面将逐一来讲解。
基础语法:select 字段列表 from 数据源;
完整语法:select 去重选项 字段列表 [as 字段别名] from 数据源 [where子句] [group by 子句] [having子句] [order by 子句] [limit子句];
去重选项::
- 去重选项就是是否对结果中完全相同的记录(所有字段数据都相同)进行去重:
- all:不去重
- distinct:去重
- 语法:select 去重选项 字段列表 from 表名;
示例:
去重前: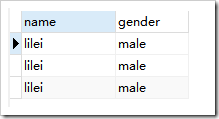 ,去重后
,去重后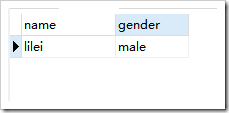
create table student(name varchar(15),gender varchar(15));
insert into student(name,gender) values("lilei","male");
insert into student(name,gender) values("lilei","male");
select * from student;
select distinct * from student;
补充:
- 注意:去重针对的是查询出来的记录,而不是存储在表中的记录。如果说仅仅查询的是某些字段,那么去重针对的是这些字段。
字段别名:
- 字段别名是给查询结果中的字段另起一个名字
- 字段别名只会在当次查询结果中生效。
- 字段别名一般都是辅助了解字段意义(比如我们定义的名字是name,我们希望返回给用户的结果显示成姓名)、简写字段名
- 语法:select 字段 as 字段别名 from 表名;
示例:
使用前: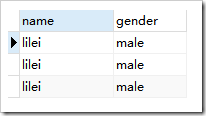 ,使用后
,使用后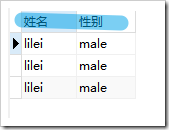
create table student(name varchar(15),gender varchar(15));
insert into student(name,gender) values("lilei","male");
insert into student(name,gender) values("lilei","male");
select * from student;
select name as "姓名",gender as "性别" from student;
数据源:
- 事实上,查询的来源可以不是“表名”,只需是一个二维表即可。那么数据来源可以是一个select结果。
- 数据源可以是单表数据源,多表数据源,以及查询语句
-
- 单表:select 字段列表 from 表名;
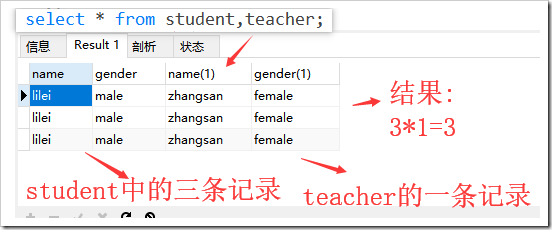
- 多表: select 字段列表 from 表名1,表名2,…; 【多表查询时是将每个表中的x条记录与另一个表y条记录组成结果,组成的结果的记录条数为x*y】【可以称为笛卡尔积】
-
- 查询语句:select 字段列表 fromr (select语句) as 表别名;【这是将一个查询结果作为一个查询的目标二维表,需要将查询结果定义成一个表别名才能作为数据源】
-
-- 示例 select name from (select * from student) as d;
where子句:
- where子句是用于筛选符合条件的结果的。
where几种语法:
- 基于值:
- = : where 字段 =值 ;查找出对应字段等于对应值的记录。(相似的,<是小于对应值,<=是小于等于对应值,>是大于对应值,>=是大于等于对应值,!=是不等于),例如:where name = ‘lilei’
- like:where 字段 like 值 ;功能与 = 相似 ,但可以使用模糊匹配来查找结果。例如:where name like ‘li%’
- = : where 字段 =值 ;查找出对应字段等于对应值的记录。(相似的,<是小于对应值,<=是小于等于对应值,>是大于对应值,>=是大于等于对应值,!=是不等于),例如:where name = ‘lilei’
- 基于值的范围:
- in: where 字段 in 范围;查找出对应字段的值在所指定范围的记录。例如:where age in (18,19,20)
- not in : where 字段 not in 范围;查找出对应字段的值不在所指定范围的记录。例如:where age not in (18,19,20)
- between x and y :where 字段 between x and y;查找出对应字段的值在闭区间[x,y]范围的记录。例如:where age between 18 and 20。
- in: where 字段 in 范围;查找出对应字段的值在所指定范围的记录。例如:where age in (18,19,20)
- 条件复合:
- or : where 条件1 or 条件2… ; 查找出符合条件1或符合条件2的记录。
- and: where 条件1 and 条件2… ; 查找出符合条件1并且符合条件2的记录。
- not : where not 条件1 ;查找出不符合条件的所有记录。
- &&的功能与and相同;||与or功能类似,!与not 功能类似。
补充:
- where是从磁盘中获取数据的时候就进行筛选的。所以某些在内存是才有的东西where无法使用。(字段别名什么的是本来不是“磁盘中的数据”(是在内存这中运行时才定义的),所以where无法使用,一般都依靠having来筛选).
select name as n ,gender from student where name ="lilei"; -- select name as n ,gender from student where n ="lilei"; --报错 select name as n ,gender from student having n ="lilei";
group by 子句:
- group by 可以将查询结果依据字段来将结果分组。
- 语法:select 字段列表 from 表名 group by 字段;
- 【字段可以有多个,实际就是二次分组】

- 【字段可以有多个,实际就是二次分组】
-- 示例 select name,gender,count(name) as "组员" from student as d group by name; select name,gender,count(name) as "组员" from student as d group by name,gender;
补充:
- 实际上,group by 的作用主要是统计(使用情景很多,比如说统计某人的总分数,学生中女性的数量。。),所以一般会配合一些统计函数来使用:
- count(x):统计每组的记录数,x是*时代表记录数,为字段名时代表统计字段数据数(除去NULL)
- max(x):统计最大值,x是字段名
- min(x):统计最小值,x是字段名
- avg(x):统计平均值,x是字段名
- sum(x):统计总和,x是字段名
- group by 字段 后面还可以跟上asc或desc,代表分组后是否根据字段排序。
having子句:
- having功能与where类似,不过having的条件判断发生在数据在内存中时,所以可以使用在内存中才发生的数据,如“分组”,“字段别名”等。
- 语法:select 字段列表 from 表名 having 条件;【操作符之类的可以参考where的,增加的只是一些“内存”中的筛选条件】
-- 示例 select name as n ,gender from student having n ="lilei"; select name,gender,count(*) as "组员" from student as d group by name,gender having count(*) >2 ;-- 这里只显示记录数>2的分组
order by 子句:
- order by 可以使查询结果按照某个字段来排序
- 语法:select 字段列表 from 表名 order by 字段 [asc|desc];
- 字段可以有多个,从左到右,后面的排序基于前面的,(比如:先按name排序,再按gender排序,后面的gender排序是针对前面name排序时name相同的数据)
- asc代表排序是递增的
- desc代表是递减的
- 也可以指定某个字段的排序方法,比如第一个字段递增,第二个递减。只需要在每个字段后面加asc或desc即可(虽然默认不加是递增,但还是加上更清晰明确)。
-- 示例 select * from student order by name; select * from student order by name,gender; select * from student order by name asc,gender desc;
limit子句:
- limit是用来限制结果数量的。与where\having等配合使用时,可以限制匹配出的结果。但凡是涉及数量的时候都可以使用limit(这里只是强调limit的作用,不要过度理解)
- 语法:select 字段列表 from 表名 limit [offset,] count;
- count是数量
- offset是起始位置,offset从0开始,可以说是每条记录的索引号
-- 示例 select * from student limit 1; select * from student limit 3,1; select * from student where name ="lilei" limit 1; select * from student where name ="lilei" limit 3,1;
更多关于MySQL相关内容感兴趣的读者可查看本站专题








