目录
- 前言
- 分析
- 数据总计
- 重复次数占比
- where 和 having 的区别
- 总结
前言
我当时正好出差在客户现场部署调试软件,有一天客户突然找到我这里,说他们现场生产的数据出现了异常的情况,最直接的表现就是 同一个标签,出现在了多个物料上,需要我配合,看怎么排查问题
分析
客户当时直接一摞重复标签的盒子码在我面前,我慌得一匹,这怕不是捅娄子了
稍加思索,现在需要做的就是,在数据库中查询出重复的标签,即对一个标签进行统计,判断出计数> 1 的即可
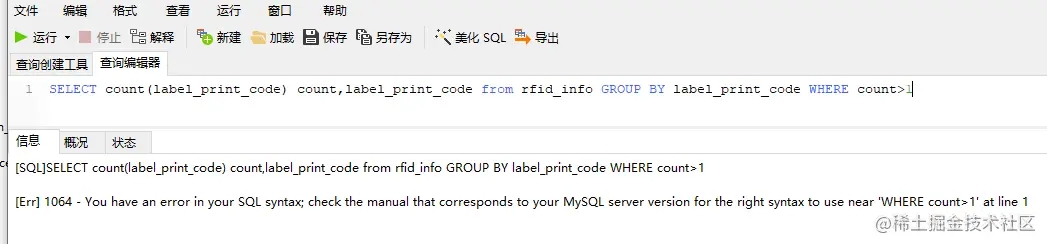
emmm,语法错误,我记得还有个Having 来着,换上试试
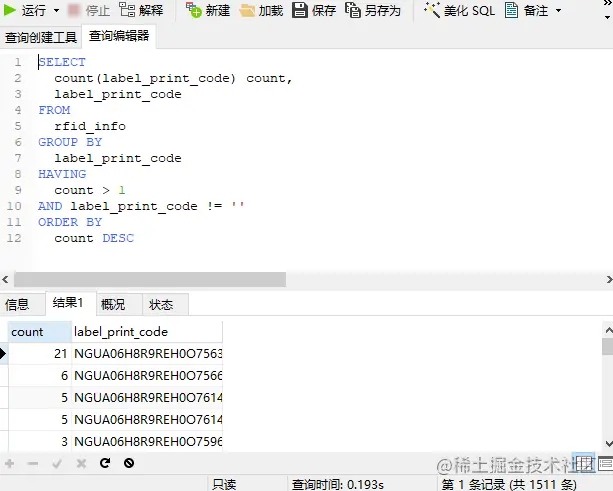
好家伙,重复的标签有 1500 多条,再统计一下总共问题的记录数量,以及再分组看看标签重复次数的占比数据
对了,先把这些重复标签数据扔个客户去追溯产品(幸好 navicat 支持复制数据)
数据总计
以上一条查询记录的结果为临时表,在此基础上,用 sum() 求和
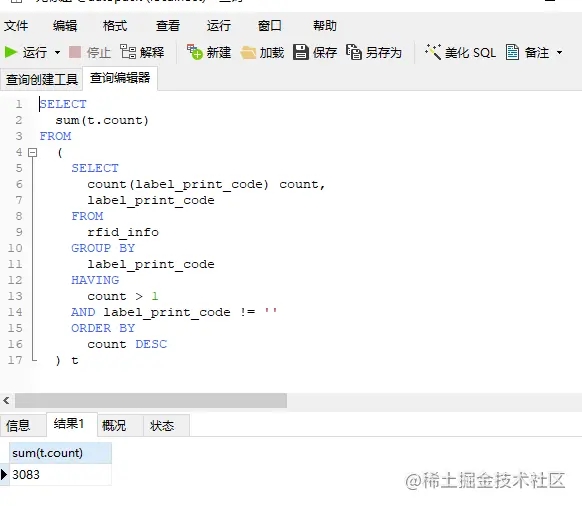
重复的记录有点多,这问题有一点点大了
重复次数占比
对之前的查询表换一个查询方式,即对 count 数据再次分组
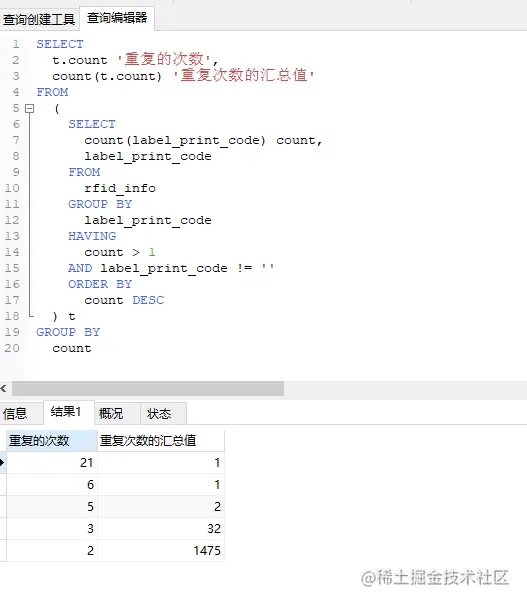
从结果来看,绝大部分问题数据重复了2次
where 和 having 的区别
Where是一个 约束声明,在查询数据库的结果返回之前对数据库中的查询条件进行约束,即在结果返回之前起作用,且where后面 不能使用聚合函数
Having是一个 过滤声明,所谓过滤是 在查询数据库的结果返回之后进行过滤,即在结果返回之后起作用,并且having后面可以使用聚合函数。
所谓 聚合函数,是对一组值进行计算并且返回单一值的函数:sum—求和,count—计数,max—最大值,avg—平均值等。
总结
在 mysql 的查询操作中,我们日常用到的,一般都是多表联查,将查询的结果当成中间表进行多次查询,对查询的结果做分组,做统计汇总等操作
如果查询操作中使用了函数计算或者是分组,典型的特征就是将原始表的多条记录合并成一条,就需要 having 对这些操作的结果进行过滤,除此之外,使用 where 对表记录进行条件过滤即可
到此这篇关于现场mysql重复记录数据的排查处理记录的文章就介绍到这了,更多相关mysql重复记录数据排查处理内容请搜索NICE源码以前的文章或继续浏览下面的相关文章希望大家以后多多支持NICE源码!