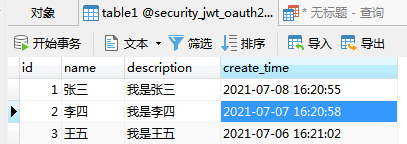
1、纵表与横表
纵表:表中字段与字段的值采用key—value形式,即表中定义两个字段,其中一个字段里存放的是字段名称,另一个字段中存放的是这个字段名称代表的字段的值。
例如,下面这张ats_item_record表,其中field_code表示字段,后面的record_value表示这个字段的值

优缺点:
横表:表结构更加的清晰明了,关联查询的一些sql语句也更容易,方便易于后续开发人员的接手,但是如果字段不够,需要新增字段,会改动表结构。
纵表:扩展性更高,如果要增加一个字段,不需要改变表结构,但是一些关联查询会更加麻烦,也不便于维护与后续人员接手。
平常开发,尽量能用横表就不要用纵表,维护成本比较高昂,而且一些关联查询也很麻烦。
2、纵表转换为横表
(1)第一步,我们先把这些字段名以及相应字段的值从纵表中取出来
select r.original_record_id,r.did,r.device_sn,r.mac_address,r.record_time, r.updated_time updated_time, (case r.field_code when 'accumulated_cooking_time' then r.record_value else '' end ) accumulated_cooking_time, (case r.field_code when 'data_version' then r.record_value else '' end) data_version, (case r.field_code when 'loop_num' then r.record_value else '' end) loop_num, (case r.field_code when 'status' then r.record_value else '' end) status from ats_item_record r where item_code = 'GONGMO_AGING'
结果:
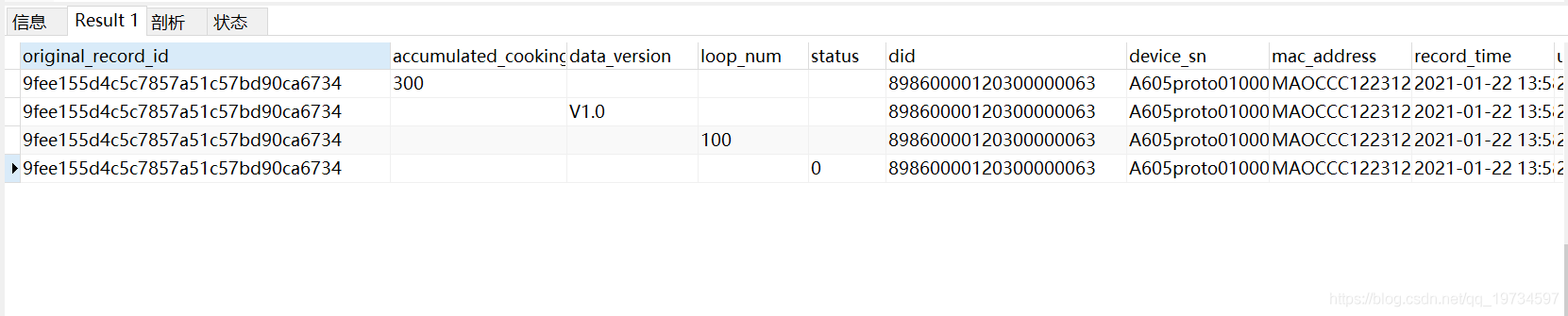
通过 case 语句,成功把字段从纵表中取出,但是此时仍算不上一个横表,我们这里的original_record_id 是记录同一行数据的唯一ID,我们这里可以通过这个字段把上面这四行合成一行记录。
注意:这里需要取出每一个字段,都要case一下,有多少个字段,就需要多少次case语句。因为一个case语句,遇到符合条件的when语句之后,后面的会不再执行。
(2)分组,合并相同行,生成横表
select * from (
select r.original_record_id,
max(r.did) did,
max(r.device_sn) device_sn,
max(r.mac_address) mac_address,
max(r.record_time) record_time,
max(r.updated_time) updated_time,
max((case r.field_code when 'accumulated_cooking_time' then r.record_value else '' end )) accumulated_cooking_time,
max((case r.field_code when 'data_version' then r.record_value else '' end)) data_version,
max((case r.field_code when 'loop_num' then r.record_value else '' end)) loop_num,
max((case r.field_code when 'status' then r.record_value else '' end)) status
from ats_item_record r
where item_code = 'GONGMO_AGING'
group by r.original_record_id
) m order by m.updated_time desc;
查询的结果:

注意:这里采用group by 分组的时候,需要给字段加上max函数。用group by 分组的时候,一般搭配聚合函数使用,常见的聚合函数:
- AVG() 求平均数
- COUNT() 求列的总数
- MAX() 求最大值
- MIN() 求最小值
- SUM() 求和
大家注意一下,我把纵表同一条记录的公共字段 r.original_record_id 放到了group by里面,这个字段在纵表中同一条记录相同、唯一,且永远不会改变(相当于以前横表的主键ID),然后把其他字段放到 max 中(因为其他字段要么是相同的,要么是取最大的就可以,要么是只有一个纵表记录有数值其他记录为空,所以这三种情况都可以直接用max),四条记录取最大的更新时间作为同一条记录的更新时间,在逻辑上也是合适的。然后我们把纵表字段 field_code 和 record_value 做了 max() 操作,因为同一条记录里面他们都是唯一存在的,不会发生同一条数据有两个相同的 field_code 记录,所以这样做 max() 也是没有任何问题的。
优化点:
最后这个SQL是可以优化一下的,我们可以把模板字段(r.original_record_id,r.did,r.device_sn,r.mac_address,r.record_time 等),从专门存放模板字段表中全部取出来(同一个逻辑纵表的字段全部取出),然后再代码里面拼接好我们的 max() 部分,作为参数拼接进去执行,这样可以做到通用,每次如果新增加模板字段,我们不需要更改这个SQL语句了(中国移动他们存放手机的参数数据就是这么干的)。
优化后的业务层(组装 SQL 模板的代码),代码如下:
@Override
public PageInfo<AtsAgingItemRecordVo> getAgingItemList(AtsItemRecordQo qo) {
//1、获取工模老化字段模板
LambdaQueryWrapper<AtsItemFieldPo> queryWrapper = Wrappers.lambdaQuery();
queryWrapper.eq(AtsItemFieldPo::getItemCode, AtsItemCodeConstant.GONGMO_AGING.getCode());
List<AtsItemFieldPo> fieldPoList = atsItemFieldDao.selectList(queryWrapper);
//2、组装查询条件
List<String> tplList = Lists.newArrayList(), conditionList = Lists.newArrayList(), validList = Lists.newArrayList();
if (!CollectionUtils.isEmpty(fieldPoList)) {
//3、组装动态max查询字段
for (AtsItemFieldPo itemFieldPo : fieldPoList) {
tplList.add("max((case r.field_code when '" + itemFieldPo.getFieldCode() + "' then r.record_value else '' end )) " + itemFieldPo.getFieldCode());
validList.add(itemFieldPo.getFieldCode());
}
qo.setTplList(tplList);
//4、组装动态where查询条件
if (StringUtils.isNotBlank(qo.getDid())) {
conditionList.add("AND did like CONCAT('%'," + qo.getDid() + ",'%')");
}
if (validList.contains("batch_code") && StringUtils.isNotBlank(qo.getBatchCode())) {
conditionList.add("AND batch_code like CONCAT('%'," + qo.getBatchCode() + ",'%')");
}
qo.setConditionList(conditionList);
}
qo.setItemCode(AtsItemCodeConstant.GONGMO_AGING.getCode());
//4、获取老化自动化测试项记录
PageHelper.startPage(qo.getPageNo(), qo.getPageSize());
List<Map<String, Object>> dataList = atsItemRecordDao.selectItemRecordListByCondition(qo);
PageInfo pageInfo = new PageInfo(dataList);
//5、组装返回结果
List<AtsAgingItemRecordVo> recordVoList = null;
if (!CollectionUtils.isEmpty(dataList)) {
recordVoList = JSONUtils.copy(dataList, AtsAgingItemRecordVo.class);
}
pageInfo.setList(recordVoList);
return pageInfo;
}
优化后的Dao层,代码如下:
public interface AtsItemRecordDao extends BaseMapper<AtsItemRecordPo> {
List<Map<String, Object>> selectItemRecordListByCondition(AtsItemRecordQo qo);
}
优化后的SQL语句,代码如下:
<select id="selectItemRecordListByCondition" resultType="java.util.HashMap"
parameterType="com.galanz.iot.ops.restapi.model.qo.AtsItemRecordQo">
SELECT * FROM (
SELECT r.original_record_id id,
max(r.did) did,
max(r.device_sn) device_sn,
max(r.updated_time) updated_time,
max(r.record_time) record_time,
<if test="tplList != null and tplList.size() > 0">
<foreach collection="tplList" item="tpl" index="index" separator=",">
${tpl}
</foreach>
</if>
FROM ats_item_record r
WHERE item_code = #{itemCode}
GROUP BY r.original_record_id
) m
<where>
<if test="conditionList != null and conditionList.size() > 0">
<foreach collection="conditionList" item="condition" index="index">
${condition}
</foreach>
</if>
</where>
ORDER BY m.updated_time DESC
</select>
模板字段表结构(ats_item_field 表),如下所示:
| 字段名 | 类型 | 长度 | 注释 |
| id | bigint | 20 | 主键ID |
| field_code | varchar | 32 | 字段编码 |
| field_name | varchar | 32 | 字段名称 |
| remark | varchar | 512 | 备注 |
| created_by | bigint | 20 | 创建人ID |
| created_time | datetime | 0 | 创建时间 |
| updated_by | bigint | 20 | 更新人ID |
| updated_time | datetime | 0 | 更新时间 |
记录表结构(ats_item_record 表),如下所示:
| 字段名 | 类型 | 长度 | 注释 |
| id | bigint | 20 | 主键ID |
| did | varchar | 64 | 设备唯一ID |
| device_sn | varchar | 32 | 设备sn |
| mac_address | varchar | 32 | 设备Mac地址 |
| field_code | varchar | 32 | 字段编码 |
| original_record_id | varchar | 64 | 原始记录ID |
| record_value | varchar | 32 | 记录值 |
| created_by | bigint | 20 | 创建人ID |
| created_time | datetime | 0 | 创建时间 |
| updated_by | bigint | 20 | 更新人ID |
| updated_time | datetime | 0 | 更新时间 |
注:original_record_id 是纵转横表后,每条记录的唯一ID,可以看做我们普通横表的主键ID一样的东西
到此 Mysql 纵表转换为横表介绍完成。
总结
到此这篇关于Mysql纵表转换为横表的文章就介绍到这了,更多相关Mysql纵表转换为横表内容请搜索NICE源码以前的文章或继续浏览下面的相关文章希望大家以后多多支持NICE源码!