前言
这里先说明一下,网上很多人说阿里规定500w数据就要分库分表。实际上,这个500w并不是定义死的,而是与MySQL的配置以及机器的硬件有关。MySQL为了提升性能,会将表的索引装载到内存中。但是当表的数据到达一定的量的时候,会导致内存无法存储这些索引,无法存储索引,就只能进行磁盘IO,从而导致性能下降。
实战调优
我这里有张表,数据有1000w,目前只有一个主键索引
CREATE TABLE `user` ( `id` int(10) NOT NULL AUTO_INCREMENT, `uname` varchar(20) DEFAULT NULL COMMENT '账号', `pwd` varchar(20) DEFAULT NULL COMMENT '密码', `addr` varchar(80) DEFAULT NULL COMMENT '地址', `tel` varchar(20) DEFAULT NULL COMMENT '电话', `regtime` char(30) DEFAULT NULL COMMENT '注册时间', `age` int(11) DEFAULT NULL COMMENT '年龄', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=10000003 DEFAULT CHARSET=utf8;

查询所有大概16s。可谓是相当慢了。通常我们一个后台系统,比如这个是一个电商平台,这个是用户表。后台管理系统,一般会查询这些用户信息,做一些操作,比如后台直接新增用户啊,或者删除用户啊这些操作。
所以这里就诞生了两个需求,一个是查询count,一个是分页查询
我们分别来测试一下count用的时间和分页查询所用的时间
select * from user limit 1, 10 //几乎不用时 select * from user limit 1000000, 10 //0.35s select * from user limit 5000000, 10 //1.7s select * from user limit 9000000, 10 //2.8s select count(1) from user //1.7s
从上面查询所用时间可以看出来,如果是分页查询的话,查询的数据越往后用时是越长的,查询count也需要1.7s。这显然是不符合我们的要求的。所以,这里我们就需要优化。首先我们这里进行索引优化试试
首先看一下这是只有主键索引的执行计划:

alter table `user` add INDEX `sindex` (`uname`,`pwd`,`addr`,`tel`,`regtime`,`age`)
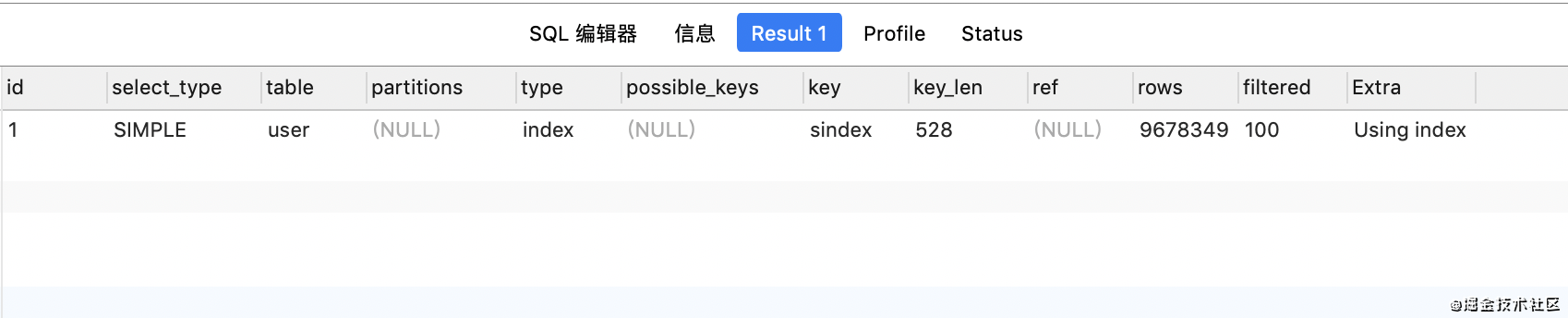
看上面的执行计划,虽然type是从all->index,走了sindex索引,但是实际上查询速度并没有发生改变。
其实,创建联合索引,是为了有条件查询的时候速度更快,而不是全表查询
select * from user where uname='6.445329111484186' //3.5s(无联合索引) select * from user where uname='6.445329111484186' //0.003s(有联合索引)
所以这就是有联合索引和无索引的差距
这里基本上可以证明,加了索引和不加索引,进行全表查询的时候,效率就是会很慢
既然索引这个结果已经不好使了,那就只能找其他方案了。根据我之前mysql面试里面讲的,count我们可以单独存储到一个表里面
CREATE TABLE `attribute` ( `id` int(11) NOT NULL, `formname` varchar(50) COLLATE utf8_bin NOT NULL COMMENT '表名', `formcount` int(11) NOT NULL COMMENT '表总数据', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;

这里说一下,这种表一般不会查所有,只会查询一条,所以建表的时候,可以建成hash
select formcount from attribute where formname='user' //几乎不用时
count就进行优化完了。如果上面有选择条件的话,就可以建立索引,通过走索引筛选的形式来查询,这样就可以不用读这个count了。
那么,count是没问题了,分页查询优化要如何优化呢?这里可以使用子查询来优化
select * from user where id>=(select id from user limit 9000000,1) limit 10 //1.7s
其实子查询这种写法,判断id,其实就是通过覆盖索引来查询。效率会大大增加。不过我这里测试是1.7s,以前在公司优化这方面的时候,比这个查询时间要低,大家也可以自己生成数据自己测试
但是如果说数据量太大了,我还是建议走es或者进行一些默认选择,count可以单独列出来
至此,一个千万级的数据分页查询的优化就完成了。
总结
到此这篇关于MySQL千万级数据表优化的文章就介绍到这了,更多相关MySQL千万级数据表优化内容请搜索NICE源码以前的文章或继续浏览下面的相关文章希望大家以后多多支持NICE源码!







