目录
- join算法
- 驱动表和非驱动表的区别
- 1、Simple Nested-Loop Join,简单嵌套-无索引的情况
- 2、Index Nested-Loop Join-有索引的情况
- 3、Block Nested-Loop Join ,join buffer缓冲区
- 缓冲区大小
- 数据量大的表和数据量小的表如何选择连接顺序
- 细节
join算法
mysql只支持一种join算法:Nested-Loop Join(嵌套循环连接),但Nested-Loop Join有三种变种:
- Simple Nested-Loop Join,简单嵌套
- Index Nested-Loop Join,索引嵌套
- Block Nested-Loop Join ,join buffer缓冲区嵌套(临时表)
驱动表和非驱动表的区别
驱动表就是主表,非驱动表就是从表,看以下sql就知道了,A就是驱动表,B就是非驱动表。
select * from A left join B
A join B 连表时,一定先查A表再查B表吗?
答案是不一定,因为mysql内部有一个优化器,它会根据你查询语句做一些优化,先查哪张表也是由优化器决定的,但可以肯定的是,先查询的那张表就是驱动表,反之就是非驱动表;关于是那张表先查的问题,我们通过看执行计划来得出结果;在前面加上explain关键字即可;
explain select * from A join B;
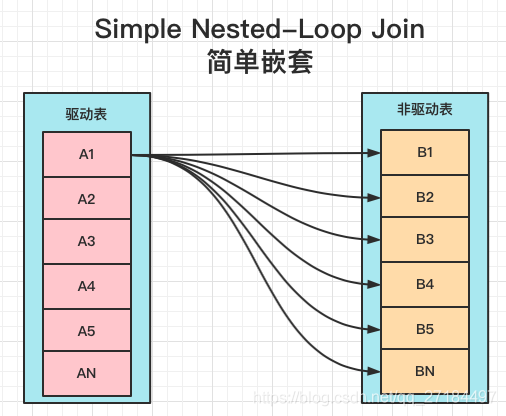
1、Simple Nested-Loop Join,简单嵌套-无索引的情况
A left join B: ,每次都是全表匹配,A表的每行数据都全表匹配一次B表,也就是说,假如我A表有10条数据,B表有1000条数据,那么查询的时候扫描次数就是10*1000,也就说查询时需要扫描10000遍才能得出数据;
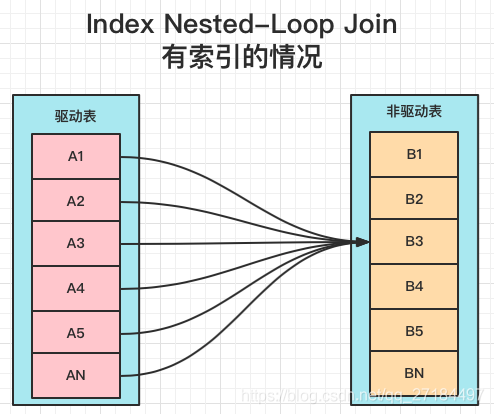
2、Index Nested-Loop Join-有索引的情况
select * from A join B on A.id=B.id where A.id = 1:在查询时,驱动表A会根据关联字段的索引进行查找,当在索引上找到符合的值,在回表进行查询,也就是说得匹配到索引后才会才会进行回表查询;
如果非驱动表B的关联关联字段B.id是主键的话,性能会非常高,如果不是主键,会进行多次回表查询,先关联索引,然后根据二级索引的主键id进行回表查询,性能上比主键要慢;
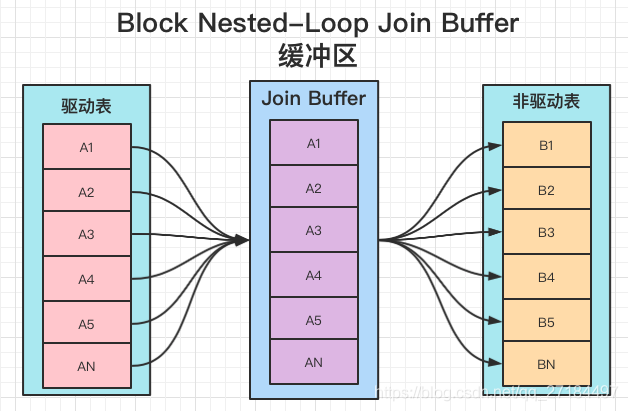
3、Block Nested-Loop Join ,join buffer缓冲区
如果有索引,会选取Index Nested-Loop Join进行连表,如果join列没有索引,就会采用Block Nested-Loop Join ,join buffer,在驱动表和非驱动表中间有个buffer的缓冲区,在查询时先将驱动表的数据缓存到buffer缓冲区内,然后批量与非驱动表进行匹配,这是一种将多次比较合并为一次比较的优化方案,注意:这里缓存的不只是关联表的列,select 后面的列也会缓存起来;
缓冲区大小
默认情况下buffer缓冲区join_biffer_size的容量为256k,如果说你的数据空间大于256k,就无法使用缓冲区了,转为最简单的循环嵌套Simple Nested-Loop Join,但是我们可以手动调整缓冲区大小来装入大容量的数据;查看join_biffer_size的sql:show variables like ‘%join_biffer_size%’
数据量大的表和数据量小的表如何选择连接顺序
最好由小表去连接大表,这样会减少扫描次数;比如大表有1000条数据,小表只有10条数据,那么最好的连接方式为:小表 join 大表;为什么要这么做呢?
- 如果是大表 join 小表,假如我们的数据在大表的第999行,那么查询数据的时候就至少得扫描999次才能查出来;
- 如果是小表 join 大表,假如我们的数据在小表的第9行,
细节
- 连表查询的时候,最好不要超过三张表,因为需要join的字段,数据类型必须一致
- 优先使用内连接来连表,外连接查询数据消耗的性能比内连接要高;
- 确保关联查询中on 后面的列或者 using()中的字段带有索引,连表时可加快数据访问
到此这篇关于浅谈mysql join底层原理的文章就介绍到这了,更多相关mysql join底层原理内容请搜索NICE源码以前的文章或继续浏览下面的相关文章希望大家以后多多支持NICE源码!











