目录
- 数据库为什么需要索引呢?
- 那索引为啥要用B+Tree的数据结构呢?
- B树插入
- 一些花里胡哨的概念
数据库为什么需要索引呢?
我们都是知道数据库的数据都是存储在磁盘上的,当我们程序启动起来的时候,就相当于一个进程运行在了机器的内存当中。所以当我们程序要查询数据时,必须要从内存出来到磁盘里面去查找数据,然后将数据写回到内存当中。但是磁盘的io效率是远不如内存的,所有查找数据的快慢直接影响程序运行的效率。
而数据库加索引的主要目的就是为了使用一种合适的数据结构,可以使得查询数据的效率变高,减少磁盘io的次数,提升数据查找的速率,而不再是愣头青式的全局遍历。
那索引为啥要用B+Tree的数据结构呢?
如果我们简单的想的话,想要快速的查找到数据,感觉hash表是最快的,根据key,hash到某个槽位上,直接一次查找就可以准确的找到数据的位置,这多快呀。但是我们在做业务时,往往只需要一条的数据需求很少,大部分的需求都是根据一定的条件查询一部分的数据,这个时候hash显示不是很合适。
我们再考虑树,比如二叉树,平衡二叉树,红黑树,B树等,他们都是二分查找,找数也快,但是不管是平衡二叉树还是优化后的红黑树,说到底他们都是二叉树,当节点多了的时候,它们的高度就会高呀,我找一个数据。根节点不是,那就找下一层,下一层还没有我就再去找下一层,这样造成的后果就是我找一个数据可能要找好几次,而每一次都是执行了一次磁盘的io,而我们的索引的目的就是要减少磁盘io呀,这样设计可不行。那我们是不是把高度变矮就可以了呢?
所以我们再考虑下B树。首先简单介绍下B树的数据结构:
首先看看B树的定义。
- 每个节点最多有m-1个关键字(可以存有的键值对)。
- 根节点最少可以只有1个关键字。
- 非根节点至少有m/2关键字。
- 每个节点中的关键字都按照从小到大的顺序排列,每个关键字的左子树中的所有关键字都小于它,而右子树中的所有关键字都大于它。
- 所有叶子节点都位于同一层,或者说根节点到每个叶子节点的长度都相同。
- 每个节点都存有索引和数据,也就是对应的key和value。
所以,根节点的关键字数量范围:1 <= k <= m-1,非根节点的关键字数量范围:m/2 <= k <= m-1。
这里的m表示阶数,阶数表示了一个节点最多有多少个孩子节点,所以描述一颗B树时需要指定它的阶数。
我们再举个例子来说明一下上面的概念,比如这里有一个5阶的B树,根节点数量范围:1 <= k <= 4,非根节点数量范围:2 <= k <= 4。
下面,我们通过一个插入的例子,讲解一下B树的插入过程,接着,再讲解一下删除关键字的过程。
B树插入
插入的时候,我们需要记住一个规则:判断当前结点key的个数是否小于等于m-1,如果满足,直接插入即可,如果不满足,将节点的中间的key将这个节点分为左右两部分,中间的节点放到父节点中即可。
例子:在5阶B树中,结点最多有4个key,最少有2个key(注意:下面的节点统一用一个节点表示key和value)。
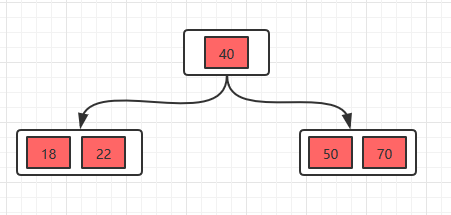
插入18,70,50,40
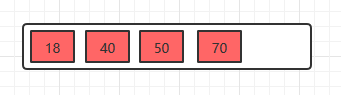
插入22
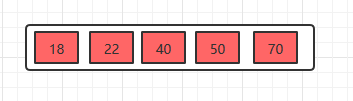
插入22时,发现这个节点的关键字已经大于4了,所以需要进行分裂,分裂的规则在上面已经讲了,分裂之后,如下。
接着插入23,25,39
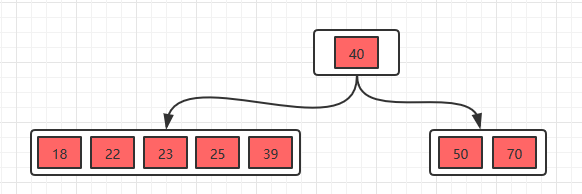
分裂,得到下面的。
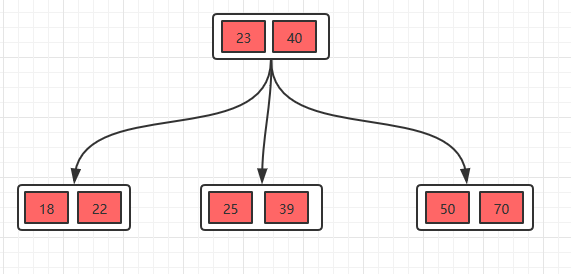
所以B树每一层的节点数会变多,相同的数据量的话,B树会比二叉树高度更低,需要的io次数就会变少,所以符合我们的索引需求。那MySQL最后为什么选择了B+树呢,比B树更优的地方在哪里呢?
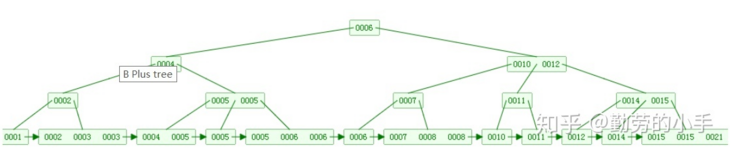
我们先看看B+树与B树不同的地方:
- B+树叶子节点包含了这棵树的所有键值,非叶子节点不存储数据,只存储索引,数据都存储在叶子节点。而B树是每个节点都存有索引和数据。
- B+树每个叶子结点都存有相邻叶子结点的指针,叶子结点本身依关键字的大小自小而大顺序链接。
如图:
第一点:当非叶子节点只存索引key而不存data时,就可以使得非叶子节点的占用空间变少,相同容量的节点可以存储更多的索引,那同样是三层的B+树,阶数就会变多,就会比B树存更多的数据。
第二点:B+树叶子节点存有相邻叶子节点的指针,想要理解这个指针的好处,我们的先知道磁盘读取数据时往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。这样做的理论依据是计算机科学中著名的局部性原理:
- 当一个数据被用到时,其附近的数据也通常会马上被使用。
- 程序运行期间所需要的数据通常比较集中。
预读的长度一般为页(page)的整倍数。页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页得大小通常为4k),主存和磁盘以页为单位交换数据。当程序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行。
现在再看B+树叶子节点的指针,我们就明白了它的用处,预读的时候可以保证连续读取的数据有序。
可能还有的同学提过B*树,它是在B+树基础上,为非叶子结点也增加链表指针。个人觉得没用B星树可能是觉得没必要吧,我们在非叶子节点又不存data,data都在叶子节点,非叶子节点了链表指针用不上。
一些花里胡哨的概念
聚簇索引和非聚簇索引:上面我们提到B+树的叶子节点存了索引key的数据data,但是mysql不同的引擎存data的选择是不一样的,MyISAM是将索引文件和真实的数据文件分两个文件各种存放,索引文件中存的data是该索引key对应的数据在数据文件中的地址值,而InnoDB则是将正式的数据存在了叶子节点中。所以聚簇和非聚簇就是区分叶子节点存的data是不是真实的(可以理解为叶子节点挤不挤?)
回表:回表也简单,但是得先明白主键索引和普通索引,上面我们所的叶子节点存真实的数据,那是只有主键索引才是这么存的,普通索引它存的data是主键索引的key。那这样我们就好理解了。比如我现在给一张表的name字段建了个普通索引,我想select * from table where name = ‘test’,这个时候我们找到test节点的时候,拿到的key只是这行数据对应的主键key,我们要得到整行的数据只能拿着这个key再去主键索引树再找一次。这个操作就叫做回表。
最左匹配原则: 当我们新建了一个组合索引时,比如(name+age),查询时使用 where name = xx and age = xx时会走组合索引,而where age = xx and name =xx则不会走。这是因为MySQL创建联合索引的规则是首先会对联合索引的最左边第一个字段排序,在第一个字段的排序基础上,然后在对第二个字段进行排序。
以上就是MySQL使用B+Tree当索引有哪些优势的详细内容,更多关于MySQL使用B+Tree当索引的优势的资料请关注NICE源码其它相关文章!