最近有一个服务出现了报警,已经让我到了忍无可忍的地步,报警信息如下:
Metric:mysql.innodb_row_lock_waits Tags:port=4306,service=xxxx diff(#1): 996>900
大概的意思是有一个数据库监控指标 innodb_row_lock_waits 目前超出了阈值900

但是尴尬的是,每次报警后去环境中查看,得到的信息都很有限,慢日志,错误日志里面都没有充分的信息可以分析,一来二去之后,我开始静下心来分析这个问题的原因。
首先这个报警信息的时间点貌似是有些规律的,我拿着最近几天的报警时间做了比对,发现还是比较有规律的,那么在系统层面有哪些任务可能会触发呢,我查找比对了相关的任务配置,发现有一个定时任务每1分钟会执行一次,但是到了这里疑问就来了,如果每1分钟执行1次,为什么在特定的时间会产生差异较大的处理结果?当然这个现象的解释是个起始。
其实要证明这一点还是蛮容易的,今天我就采取了守株待兔的模式,我在临近报警的时间前后打开了通用日志,从日志输出来看,操作的频率还是相对有限的。
很快得到了规律性的报警,于是我开始抓取相关的通用日志记录,比如11:18分,我们可以采用如下的模式得到相关的日志,首先得到一个临时的通用日志文件,把各种DML和执行操作都网罗进来。
cat general.log|grep -E “insert|delete|update|select|exec” > general_tmp.log
我们以11:18分为例,可以在前后1两分钟做比对,结果如下:
# less general_tmp.log |grep “11:18″|wc -l
400
# less general_tmp.log |grep “11:17″|wc -l
666
# less general_tmp.log |grep “11:16″|wc -l
15
发现在报警的那1分钟前后,数量是能够对得上的。
这个表的数据量有200多万,表结构如下:
CREATE TABLE `task_queue` ( `AccID` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增ID', `TaskStepID` bigint(20) DEFAULT NULL COMMENT '任务步骤ID task_step_conf', `QOrder` int(11) DEFAULT NULL COMMENT '队列排序 task_step_confi.Step_ID', `QState` tinyint(4) DEFAULT '1' COMMENT '队列状态 1:待执行 2:执行中 3:执行成功 4:执行失败', `QExcCount` int(11) DEFAULT '1' COMMENT '执行次数', `CrtTime` datetime DEFAULT NULL COMMENT '创建时间', `ModTime` datetime DEFAULT NULL COMMENT '修改时间', PRIMARY KEY (`AccID`), KEY `idx_taskstepid` (`TaskStepID`), KEY `idx_qstate` (`QState`) ) ENGINE=InnoDB AUTO_INCREMENT=3398341 DEFAULT CHARSET=utf8
在日志中根据分析和比对,基本能够锁定SQL是在一类Update操作上面,SQL的执行计划如下:
>>explain update task_queue set QState=1,QExcCount=QExcCount+1,modtime=now() where QState=0 and taskstepid =411\G *************************** 1. row *************************** id: 1 select_type: UPDATE table: task_queue partitions: NULL type: index_merge possible_keys: idx_taskstepid,idx_qstate key: idx_qstate,idx_taskstepid key_len: 2,9 ref: NULL rows: 11 filtered: 100.00 Extra: Using intersect(idx_qstate,idx_taskstepid); Using where; Using temporary
这个执行结果中key_len是2,9,是和以往的ken_len计算法则不一样的。 其中Extra列已经给出了明确的提示,这是一个intersect处理,特别的是它是基于二级索引级别的处理,在优化器层面是有一个相关的参数index_merge_intersection。
我们知道在MySQL中主键是一等公民,而二级索引最后都会映射到主键层面处理,而索引级别的intersect其实有点我们的左右手,左手对应一些数据结果映射到一批主键id,右手对应一些数据结果映射到另外一批主键id,把两者的主键id值进行intersect交集计算,所以在当前的场景中,索引级别的intersect到底好不好呢?
在此我设想了3个对比场景进行分析,首先这是一个update语句,我们为了保证后续测试的可重复性,可以转换为一个select语句。
select * from task_queue where QState=0 and taskstepid =411;
所以我们的对比测试基于查询语句进行比对分析。
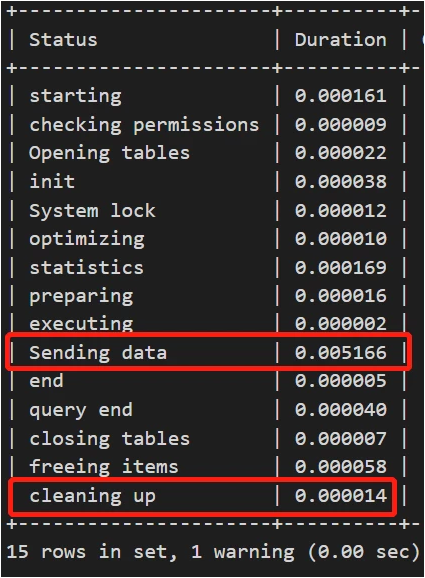
场景1:优化器保持默认index_merge_intersection开启,基于profile提取执行明细信息
>explain select * from task_queue where QState=0 and taskstepid =411\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: task_queue partitions: NULL type: index_merge possible_keys: idx_qstate,idx_taskstepid key: idx_qstate,idx_taskstepid key_len: 2,9 ref: NULL rows: 11 filtered: 100.00 Extra: Using intersect(idx_qstate,idx_taskstepid); Using where 1 row in set, 1 warning (0.00 sec)
profile信息为:
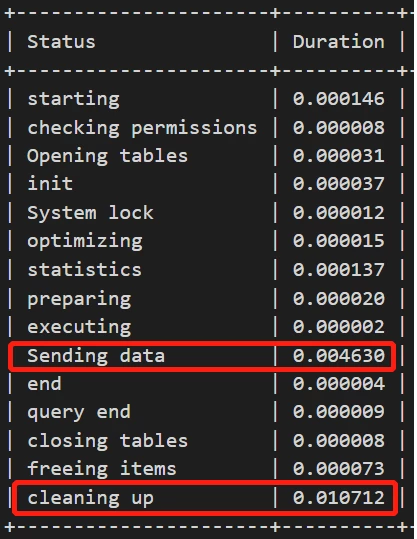
场景2:优化器关闭index_merge_intersection,基于profile进行对比
>set session optimizer_switch='index_merge_intersection=off'; >explain select * from task_queue where QState=0 and taskstepid =411\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: task_queue partitions: NULL type: ref possible_keys: idx_qstate,idx_taskstepid key: idx_qstate key_len: 2 ref: const rows: 1451 filtered: 0.82 Extra: Using where 1 row in set, 1 warning (0.00 sec)
profile信息为:
场景3:重构索引,进行比对分析
根据业务逻辑,如果创建一个复合索引,是能够大大减少结果集的量级的,同时依然保留 idx_ qsta te 索引,使得一些业务依然能够正常使用。
>alter table task_queue drop key idx_taskstepid;
>alter table task_queue add key `idx_taskstepid` (`TaskStepID`,QState);
explain select * from task_queue where QState=0 and taskstepid =411\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: task_queue
partitions: NULL
type: ref
possible_keys: idx_qstate,idx_taskstepid
key: idx_taskstepid
key_len: 11
ref: const,const
rows: 1
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
profile信息为:
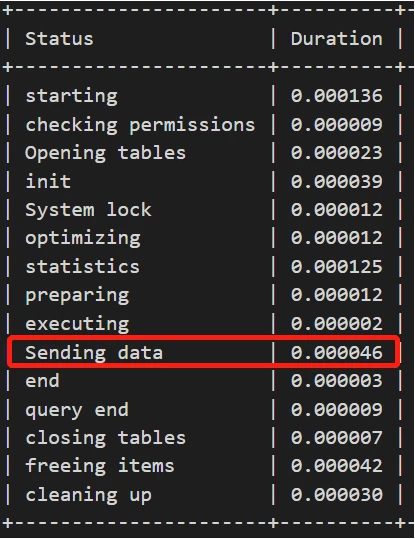
可以明显看到通过索引重构,“Sending data”的部分少了两个数量级
所以接下里的事情就是进一步进行分析和验证,有理有据,等待的过程也不再彷徨,一天过去了,再没有收到1条报警,再次说明在工作中不要小看这些报警。
总结
到此这篇关于关于MySQL报警分析处理的文章就介绍到这了,更多相关MySQL报警处理内容请搜索NICE源码以前的文章或继续浏览下面的相关文章希望大家以后多多支持NICE源码!