1、使用方式:
(1)EXISTS用法
select a.batchName,a.projectId from ucsc_project_batch a where EXISTS (select b.id from ucsc_project b where a.projectId = b.id)
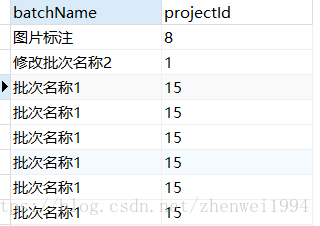
上面这条SQL的意思就是:以ucsc_project_batch为主表查询batchName与projectId字段,其中projectId字段存在于ucsc_project表中。
EXISTS 会对外表ucsc_project_batch进行循环查询匹配,它不在乎后面的内表子查询的返回值是什么,只在乎有没有存在返回值,存在返回值,则条件为真,该条数据匹配成功,加入查询结果集中;如果没有返回值,条件为假,丢弃该条数据。
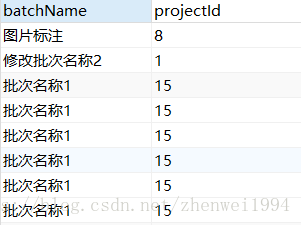
例如我们这里改变一下子查询的查询返回字段,并不影响外查询的查询结果:
select a.batchName,a.projectId from ucsc_project_batch a where EXISTS (select b.companyId,b.name from ucsc_project b where a.projectId = b.id)
(2)IN用法
select a.batchName,a.projectId from ucsc_project_batch a where a.projectId in (select b.id from ucsc_project b)
上面这条SQL的查询结果与刚才的EXISTS的结果一样,查询的意思也一样。
2、注意点:
(1)EXISTS写法需要注意子查询中的条件语句一般需要带上外查询的表做关联,不然子查询的条件可能会一直为真,或者一直为假,外查询的表进行循环匹配的时候,要么全部都查询出来,要么一条也没有。
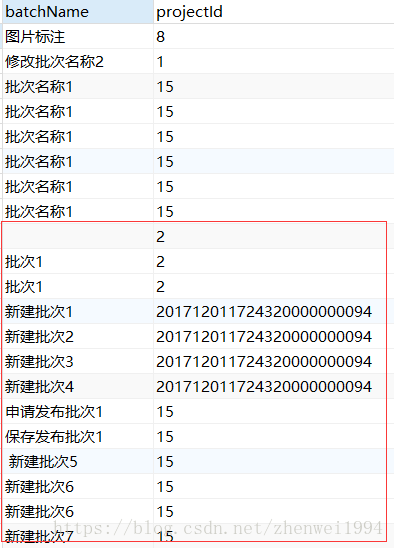
select a.batchName,a.projectId from ucsc_project_batch a where EXISTS (select b.id from ucsc_project b)
比如上述这种写法,由于ucsc_project 表存在值,子查询的条件一直为真,ucsc_project_batch 每条数据进行循环匹配的时候,都能匹配成功,查询出来的结果就成为了ucsc_project_batch整张表数据。
select a.batchName,a.projectId from ucsc_project_batch a where EXISTS (select b.id from ucsc_project b where b.id is null)
这种写法,子查询肯定查不到结果,所以子查询的条件为假,外查询的每条数据匹配失败,整个查询结果为空

(2)IN语句在mysql中没有参数个数的限制,但是mysql中SQL语句有长度大小限制,整段最大为4M
(3)EXISTS的子查询语句不在乎查询的是什么,只在乎有没有结果集存在,存在则整个子查询可以看作一个条件为真的语句,不然就是一个条件为假的语句
(4)IN语句对于子查询的返回字段只能由一个,不然会报错:
select a.batchName,a.projectId from ucsc_project_batch a where a.projectId in (select b.id,b.companyId from ucsc_project b)
[Err] 1241 – Operand should contain 1 column(s)
3、场景选择
外查询表大,子查询表小,选择IN;外查询表小,子查询表大,选择EXISTS;若两表差不多大,则差不多。
(1)IN中的SQL查询只会查询一次,然后把结果集存在临时文件中,然后再与外层查询sql进行匹配,其中外查询与子查询都可以使用索引
select a.batchName,a.projectId from ucsc_project_batch a where a.projectId in (select b.id from ucsc_project b)

等价于:
$result = [];
$ucsc_project_batch = "select a.batchName,a.projectId from ucsc_project_batch a";
$ucsc_project = "select b.id from ucsc_project b";
for($i = 0;$i < $ucsc_project_batch .length;$i++){
for($j = 0;$j < $ucsc_project .length;$j++){
if($ucsc_project_batch [$i].projectId== $ucsc_project [$j].id){
$result[] = $ucsc_project_batch [$i];
break;
}
}
}
(2)EXISTS会对外查询的表ucsc_project_batch 进行循环匹配,执行ucsc_project_batch.length次,其中子查询可以使用索引,外查询全表扫描
select a.batchName,a.projectId from ucsc_project_batch a where EXISTS (select b.id from ucsc_project b where a.projectId = b.id)

等价于:
$result = [];
$ucsc_project_batch = "select a.batchName,a.projectId from ucsc_project_batch a ";
for ($i = 0; $i < $ucsc_project_batch . length; $i++) {
if (exists($ucsc_project_batch [$i] . projectId)) {//执行select b.id from ucsc_project b where a.projectId=b.id
$result[] = $ucsc_project_batch [$i];
}
}
通过两个的伪代码分析可知:子查询的表大的时候,使用EXISTS可以有效减少总的循环次数来提升速度;当外查询的表大的时候,使用IN可以有效减少对外查询表循环遍历来提升速度。
总结
到此这篇关于mysql中EXISTS和IN的使用方法比较的文章就介绍到这了,更多相关mysql EXISTS和IN比较内容请搜索NICE源码以前的文章或继续浏览下面的相关文章希望大家以后多多支持NICE源码!

