目录
- Kill 指令执行原理
- 指令执行特点
- kill query 执行原理
- Kill Connection 执行原理
- 是否可以被中断判断
- 可以被中断的场景:正常执行或者处于可以被唤醒的阻塞等待状态。
- 不可以被中断的场景:被阻塞且不能被唤醒。
- 其他
- 服务器线程执行流程
- 客户端执行流程
kill 指令有两种写法 ” kill query + 线程 id “、” kill connection(可缺省) + 线程 id “。分别表示关闭指定线程正在执行的语句、断开指定线程连接的客户端(如果有正在执行的操作会先停止执行的操作再关闭连接)。但某些情况下使用 kill query 后使用 show processlist 查看 Command 列为 killed(表示 正在等待回收线程回收,还未回收),这是为什么呢?
在解答这个问题前,需要知道服务器端处理请求的线程是如何执行的,以及 kill 命令是如何作用的。
Kill 指令执行原理
指令执行特点
1、 一个语句执行过程中有多处 ” 埋点 “,在这些 ” 埋点 ” 的地方判断线程状态,如果发现线程状态是 THD:KILL_QUERY,才开始进入语句终止逻辑;
2、如果处于等待状态,必须是一个可以被唤醒的等待,否则根本不会执行到“埋点”处;
3、语句从开始进入终止逻辑,到终止逻辑完全完成,是有一个过程的。
kill query 执行原理
kill query 主要进行了两步操作:
1、把线程的运行状态改成 THD::KILL_QUERY(将变量 killed 赋值为 THD::KILL_QUERY);
2、给会话的执行线程发一个信号,退出阻塞状态,处理这个状态。
Kill Connection 执行原理
1、把 12 号线程状态设置为 KILL_CONNECTION;
2、关掉 12 号线程的网络连接。
是否可以被中断判断
1、一般正常执行的语句在执行 kill query 后都会先将状态从 killed 改成 KILL_QUERY,然后执行到 ” 埋点 ” 处被判断中断执行。
2、如果是处于阻塞的语句,那么需要去查看当前阻塞等待的状态是否可以被唤醒,如果可以被唤醒才有机会中断当前语句。
可以被中断的场景:正常执行或者处于可以被唤醒的阻塞等待状态。
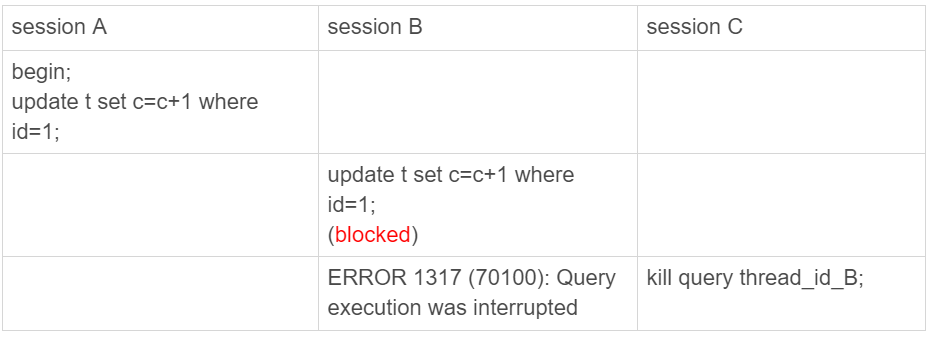
因为等行锁时,使用的是 pthread_cond_timedwait 函数,所以这个等待状态可以被唤醒。可以被 kill query 直接唤醒继续执行直到 “埋点” 判断。
不可以被中断的场景:被阻塞且不能被唤醒。
例子:因并发线程被使用完而造成的阻塞。
将参数 innodb_thread_concurrency(MySQL 的并发线程数)设为 2。然后执行下面的操作:

在 sessionD 执行 kill query C 后 sessionC 并没有退出阻塞。
- 问题1:为什么使用 kill query 没有中断阻塞?
答:因为这种阻塞从微观上来看并不是阻塞,而是一种循环判断。每隔 10 毫秒判断一下是否可以进入 Innodb 执行,如果不行,就调用 nanosleep 函数进入 sleep 状态。也就是说,虽然线程的状态已经被设置成了 KILL_QUERY(THD::KILL_QUERY),但是在这个等待进入 InnoDB 的循环过程中,并没有执行到 “埋点”,也就没有去判断线程的状态,因此根本不会进入终止逻辑阶段。所以也就不会中断。
- 问题2:如果此时使用 show processlist 来查看,会发现 Command 列为 killed,这是为什么?
答:kill query 语句会将线程状态设为 KILL_QUERY ,这时会因为这个状态而被判断为正在执行中断逻辑,所以 Command 值为 killed。
- 问题3:为什么使用 kill connection 可以中断阻塞?
答:因为 kill connection 会直接关闭线程的网络连接,强制关闭,所以这时候 session C 收到了断开连接的提示。
- 问题4:如果只是使用 kill query 什么时候才能中断阻塞?
答:只有等到会话被分配了线程后执行到 “ 埋点 ” 后判断然后执行中断逻辑才会退出。而被分配线程后并不是就一定会中断,如果在执行到 “埋点” 之前让出线程,那么就会再次等待。MySQL 的线程是多路复用的。
其他
1、其实除了上面使用 kill 命令来终止阻塞状态外,还可以直接在该会话中使用 “ ctrl+c ” 来中止阻塞,这又是什么原理呢?
答:首先要知道客户端操作服务端是客户端开启一个线程,让这个线程去处理,发送请求数据,通过网络传输到服务端,服务端再分配线程去处理。而 “ctrl +c ” 是让客户端另开一个连接,并发送一个 kill query 的命令。所以虽然我们看来是中断了阻塞,但是处理上一个连接的服务端线程并一定就会被中断。
2、为什么在指定库名连接时会很慢?如下图:

答:这是由于 MySQL 默认开启了自动补全功能(输入表名时可以使用 tab 自动补全)。其实现是在连接数据库多执行一些操作:
1、执行 show databases;
2、切到 db1 库,执行 show tables;
3、把这两个命令的结果用于构建一个本地的哈希表。(最耗时)
这个功能可以在命令中加上 -A 关闭。同时使用 -quick 也可以关闭。但是使用 -quick 可能会使客户端性能降低。这是为什么?这就要说到数据在服务器端与客户端发送的流程了。
服务器线程执行流程
客户端首先与服务器端验证用户名和密码,通过后正式建立连接,然后客户端发送请求,服务器端从线程池中取一个线程来处理。处理的过程:
1、获取一行,写到 net_buffer 中。这块内存的大小是由参数 net_buffer_length 定义的,默认是 16k。
2、重复获取行,直到 net_buffer 写满,调用网络接口发出去。
3、如果发送成功,就清空 net_buffer,然后继续取下一行,并写入 net_buffer。
4、如果发送函数返回 EAGAIN 或 WSAEWOULDBLOCK,就表示本地网络栈(socket send buffer)写满了,进入等待。直到网络栈重新可写,再继续发送。
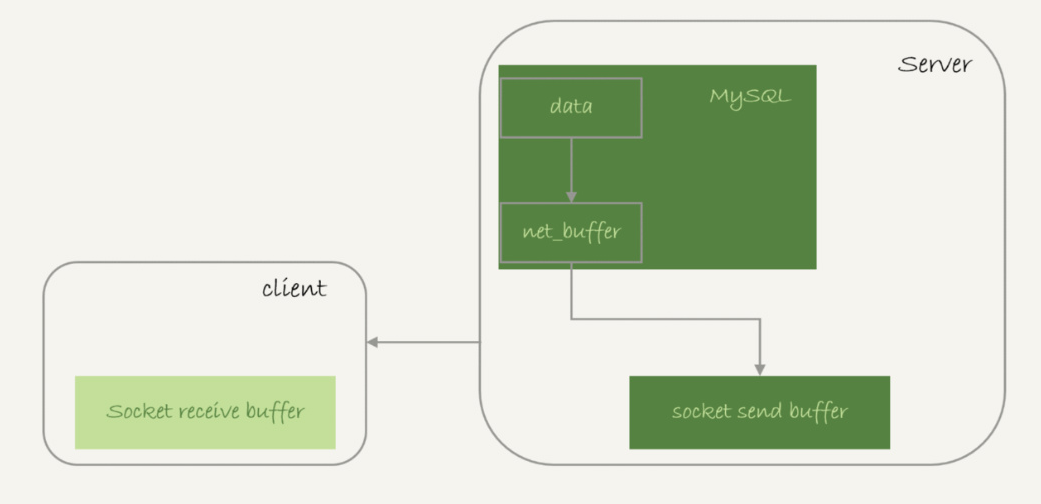
从上面的流程可以知道,如果一次要发送的数据量超过 socket send buffer 空间,那么就会拆分开来发送,并不会发生 ” 内存打爆 ” 的情况。由此我们可以知道,MySQL 是边读边发的。
1、如果请求返回的数据量很大,那么在等待返回的过程中使用 show processlist 查看 State 列的值就会为 ” Sending to client”,表示服务器端的网络栈写满了。
这是因为 Sate 列值的变化是在查询请求到达开始执行就会变为 ” Sending data “,如果网络栈写满发就会切换为 ” Sending to client “,表示 ” 正在等待客户端接收结果 “。” Sending data ” 可能处于线程执行过程中的任意阶段,比如因为锁而阻塞的场景。


2、如果 show processlist 的 State 列一直为 ” Sending to Client “,那么可以
1)查看这条SQL,判断是否可以优化,减少返回值。
2)将 net_buffer_length 设的大一些,来避免或者减少发送阻塞的时间。
客户端执行流程
在开始客户端会创建线程去连接服务器端,然后接收服务端返回的数据,客户端接收服务器端返回的数据有两种方式:
1、本地缓存。在本地开一片内存,先把结果存起来。如果用 API 开发,对应的就是 mysql_store_result 方法。建议在客户端处理量大时使用本地缓存。可以使用 mysql -h$host -P$port -u$user -p$pwd -e “select * from db1.t” > $target_file 将返回的数据保存到指定文件。
2、不缓存,读一个处理一个。如果用 API 开发,对应的就是 mysql_use_result 方法。
回到上面的问题,为什么使用 -quick 可能会导致客户端性能下降?这是因为客户端默认使用缓存来接收,所以在客户端正在处理其他数据时就可以先进行缓存,等到后面直接读取缓存就可以了。而使用 quick 就会使客户端接收不使用缓存,那么如果客户端正在执行其他操作这个数据就会被阻塞,并且服务器端对应的线程也会因为没有收到客户端的反馈而没有中断这次事务,这次事务涉及到的资源锁也没有释放,造成并发问题,影响效率。除此之外, quick 还有三个效果。
1、就是前面提到的,跳过表名自动补全功能。
2、客户端接收数据使用不缓存的方式。而 mysql_store_result 方法需要申请本地内存来缓存查询结果,如果查询结果太大,会耗费较多的本地内存,可能会影响客户端本地机器的性能;
3、不会把执行命令记录到本地的命令历史文件。
以上就是详解MySQL kill 指令的执行原理的详细内容,更多关于MySQL kill 指令的资料请关注NICE源码其它相关文章!








