1.问题引入
假设一个场景,一张用户表,包含3个字段。id,identity_id,name。现在身份证号identity_id和姓名name有很多重复的数据,需要删除只保留一条有效数据。
2.模拟环境
1.登入mysql数据库,创建一个单独的测试数据库mysql_exercise
create database mysql_exercise charset utf8;
2.创建用户表users
create table users(
id int auto_increment primary key,
identity_id varchar(20),
name varchar(20) not null
);
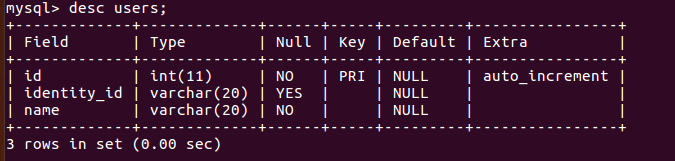
3.插入测试数据
insert into users values(0,'620616199409206512','张三'), (0,'620616199409206512','张三'), (0,'62062619930920651X','李四'), (0,'62062619930920651X','李四'), (0,'620622199101206211','王五'), (0,'620622199101206211','王五'), (0,'322235199909116233','赵六');
可以多执行几次,生成较多重复数据。
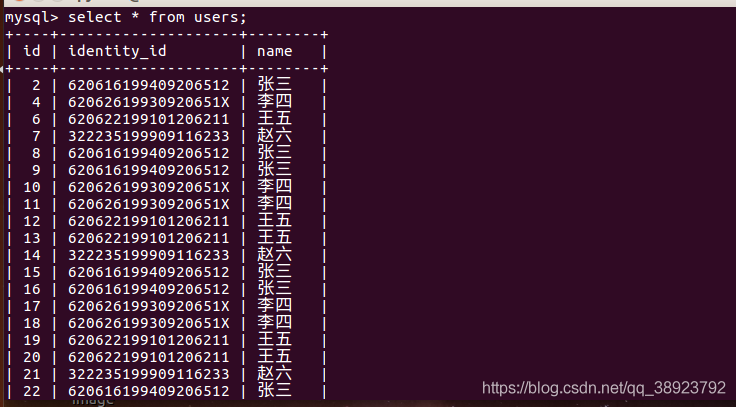
4.解决思路
(1)根据身份证号和name进行分组;
(2)取出分组后的最大id(或最小id);
(3)删除除最大(或最小)id以外的其他字段;
5.第一次尝试(失败!!!)
delete from users where id not in (select max(id) from users group by identity_id,name);
报错:
1093 (HY000): You can’t specify target table ‘users’ for update in FROM clause

因为在MYSQL里,不能先select一个表的记录,再按此条件进行更新和删除同一个表的记录。
解决办法是,将select得到的结果,再通过中间表select一遍,这样就规避了错误,
这个问题只出现于mysql,mssql和oracle不会出现此问题。
所以我们可以先将括号里面的sql语句先拿出来,先查到最大(或最小)id。
select max_id from (select max(id) as max_id from users group by identity_id,name);
接着,又报错了!!!
ERROR 1248 (42000): Every derived table must have its own alias
意思是说:提示说每一个衍生出来的表,必须要有自己的别名!
执行子查询的时候,外层查询会将内层的查询当做一张表来处理,所以我们需要给内层的查询加上别名

继续更正:
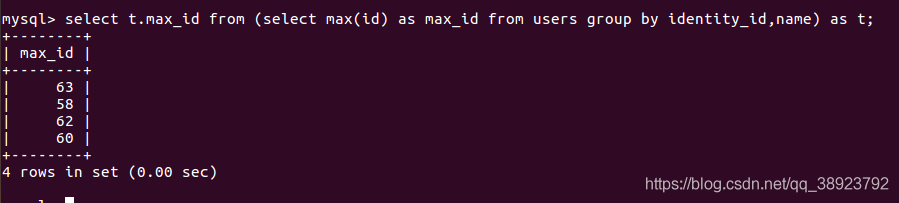
给查询到的最大(或最小id)结果当做一张新的表,起别名t,并查询t.mix_id。
select t.max_id from (select max(id) as max_id from users group by identity_id,name) as t;
可以成功查到最大(或最小)id了,如下图:
6.第二次尝试(成功!!!)
delete from users where id not in ( select t.max_id from (select max(id) as max_id from users group by identity_id,name) as t );
执行结果:
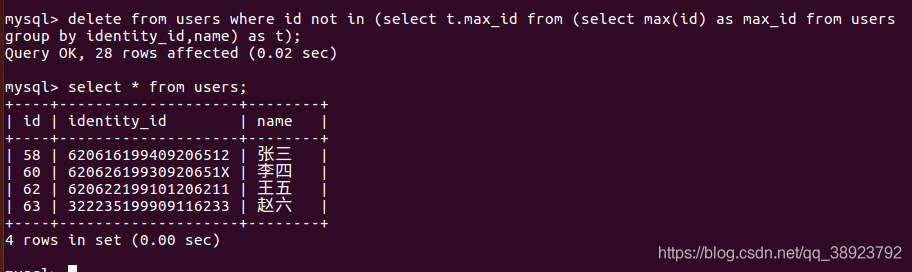
成功将重复的数据删除,只保留了最后一次增加的记录。同理也可以保留第一次添加的记录(即删除每个分组里面除最小id以外的其他条记录)
3.知识拓展一:更新数据
其他场景应用:要将用户表user_info里名字(name)为空字符串(“”)的用户的状态(status)改成”0″
update user_info set status='0' where user_id in (select user_id from user_info where name='')
同样报了如下错误:
You can’t specify target table ‘user_info’ for update in FROM clause
因为在MYSQL里,不能先select一个表的记录,再按此条件进行更新和删除同一个表的记录,解决办法是,将select得到的结果,再通过中间表select一遍,这样就规避了错误。
以下两种均可!!!
update user_info set status='0' where user_id in (select user_id from (select user_id from user_info where name = '') t1);
下面这种也可,细微差别,别名可带as可不带,t1.user_id 直接和内层的user_id对应也可以。
update user_info set status='0' where user_id in (select t1.user_id from (select user_id from user_info where name='') as t1);
3.1 分步骤解析
(1)将以下查询结果作为中间表:
select user_id from user_info where name='';
(2)再查询一遍中间表作为结果集:
select user_id from (select user_id from user_info where name='') as t;
(3)更新数据
update user_info set status='0' where user_id in (select user_id from (select user_id from user_info where name='') as t1);
4.拓展练习:删除重复数据
编写一个 SQL 查询,来删除 Person 表中所有重复的电子邮箱,重复的邮箱里只保留 Id 最小 的那个。
+----+------------------+ | Id | Email | +----+------------------+ | 1 | john@example.com | | 2 | bob@example.com | | 3 | john@example.com | +----+------------------+
Id 是这个表的主键。
例如,在运行你的查询语句之后,上面的 Person 表应返回以下几行:
+----+------------------+ | Id | Email | +----+------------------+ | 1 | john@example.com | | 2 | bob@example.com | +----+------------------+
解答一:
delete from Person where Id not in ( select t.min_id from ( select min(Id) as min_id from Person group by Email ) as t );
解答二:
delete p1 from Person as p1,Person as p2 where p1.Email=p2.Email and p1.Id > p2.Id;
总结
到此这篇关于mysql数据库删除重复数据的方法只保留一条的文章就介绍到这了,更多相关mysql删除重复数据内容请搜索NICE源码以前的文章或继续浏览下面的相关文章希望大家以后多多支持NICE源码!











