目录
- 一、前言:
- 二、第一个思路建索引
- 三、INSTR
- 附:Like是否使用索引?
- 总结
一、前言:
我建了一个《学生管理系统》,其中有一张学生表和四张表(小组表,班级表,标签表,城市表)进行联合的模糊查询,效率非常的低,就想了一下如何提高like模糊查询效率问题
注:看本篇博客之前请查看:Mysql中如何查看Sql语句的执行时间
二、第一个思路建索引
1、like %keyword 索引失效,使用全表扫描。
2、like keyword% 索引有效。
3、like %keyword% 索引失效,使用全表扫描。
使用explain测试了一下:
原始表(注:案例以学生表进行举例)
-- 用户表
create table t_users(
id int primary key auto_increment,
-- 用户名
username varchar(20),
-- 密码
password varchar(20),
-- 真实姓名
real_name varchar(50),
-- 性别 1表示男 0表示女
sex int,
-- 出生年月日
birth date,
-- 手机号
mobile varchar(11),
-- 上传后的头像路径
head_pic varchar(200)
);
建立索引
#create index 索引名 on 表名(列名); create index username on t_users(username);
like %keyword% 索引失效,使用全表扫描
explain select id,username,password,real_name,sex,birth,mobile,head_pic from t_users where username like '%h%';

like keyword% 索引有效。
explain select id,username,password,real_name,sex,birth,mobile,head_pic from t_users where username like 'wh%';

like %keyword 索引失效,使用全表扫描。

三、INSTR
这个我最开始都没听说过,今天查阅了一下资料,才知道有这个宝贝东西,
instr(str,substr):返回字符串str串中substr子串第一个出现的位置,没有找到字符串返回0,否则返回位置(从1开始)
#instr(str,substr)方法
select id,username,password,real_name,sex,birth,mobile,head_pic
from t_users
where instr(username,'wh')>0 #0.00081900
#模糊查询
select id,username,password,real_name,sex,birth,mobile,head_pic
from t_users
where username like 'whj'; # 0.00094650
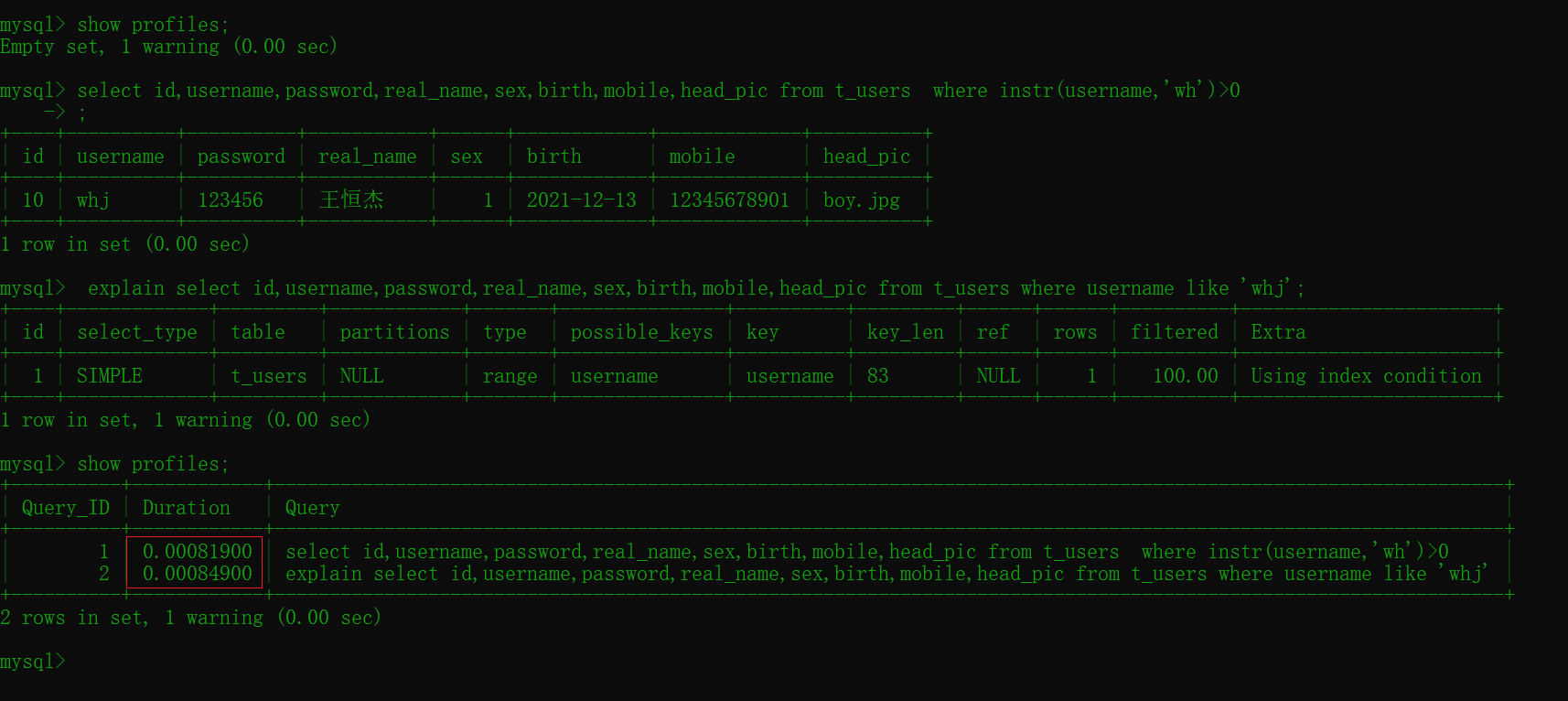
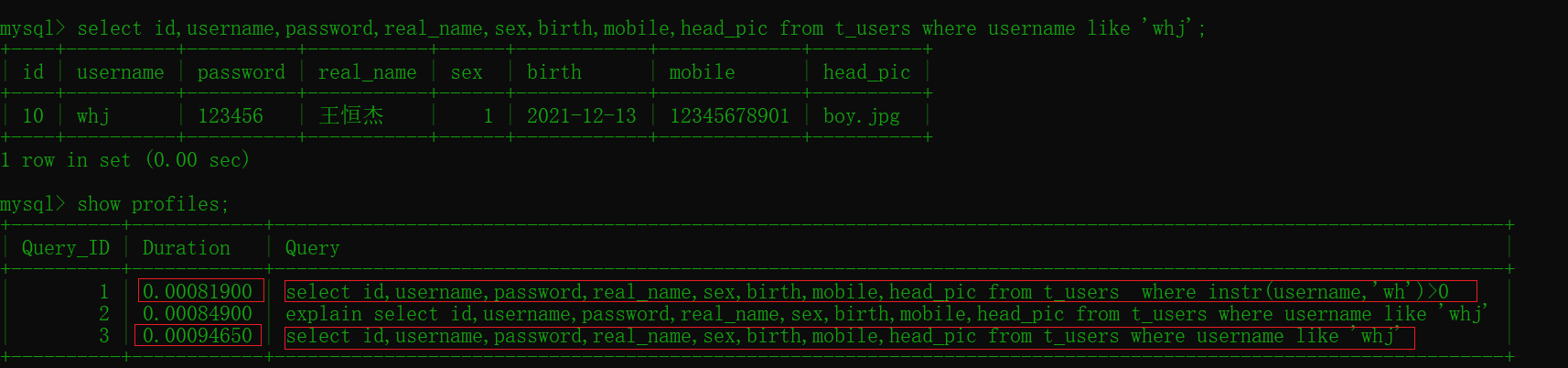
比较两个效率差距不大主要原因是数据较少,最好多准备点原始数据进行测试效果最佳
附:Like是否使用索引?
1、like %keyword 索引失效,使用全表扫描。但可以通过翻转函数+like前模糊查询+建立翻转函数索引=走翻转函数索引,不走全表扫描。
2、like keyword% 索引有效。
3、like %keyword% 索引失效,也无法使用反向索引。
总结
到此这篇关于MySQL中Like模糊查询速度太慢该如何进行优化的文章就介绍到这了,更多相关MySQL Like模糊查询慢优化内容请搜索NICE源码以前的文章或继续浏览下面的相关文章希望大家以后多多支持NICE源码!







