目录
- 一、索引类型
- 1.B+树
- 2.MyISAM和InnoDB的B+树索引实现方式的区别(聚簇索引和非聚簇索引)?
- 3.非聚簇索引
- 4.聚簇索引的优缺点
- 5.哈希索引
- 6.自适应哈希索引
一、索引类型
1.B+树
为什么是B+树而不是B树?
首先看看B树和B+树在结构上的区别
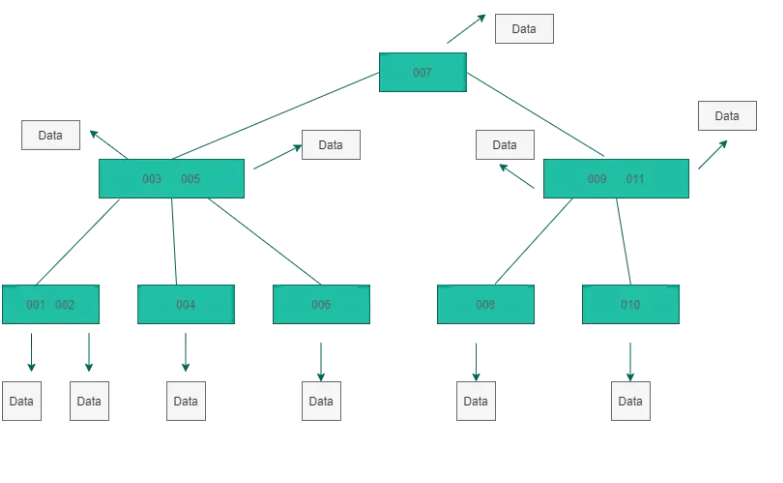
B树结构:
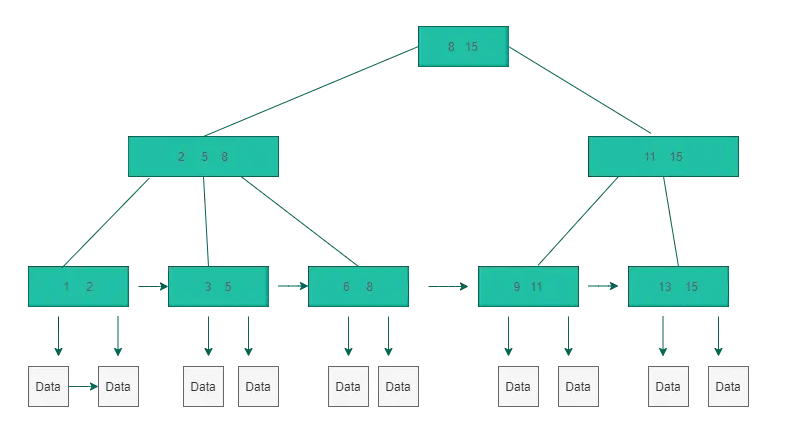
B+树:
可以看到:
- B树在每个节点上都有卫星数据(数据表中的一行数据),而B+树只在叶子节点上有卫星数据。这意味着相同大小的磁盘扇区,B+树可以存储的叶子节点更多,磁盘IO次数更少;同样也意味着B+树的查找效率更稳定,而B树数据查询的最快时间复杂度是O(1)。
- B树的每个节点只出现一次,B+树的所有节点都会出现在叶子节点中。B+树的所有叶子节点形成一个升序链表,适合区间范围查找,而B树则不适合。
2.MyISAM和InnoDB的B+树索引实现方式的区别(聚簇索引和非聚簇索引)?
首先需要了解聚簇索引和非聚簇索引。
聚簇索引:
在聚簇索引中,叶子页包含了行的全部数据,节点页值包含索引列。InnoDB通过主键聚集数据,如果没有定义主键则选择一个唯一的非空索引列代替;如果没有这样的索引,InnoDB会隐式定义一个主键来作为聚簇索引。
聚簇索引的数据分布:
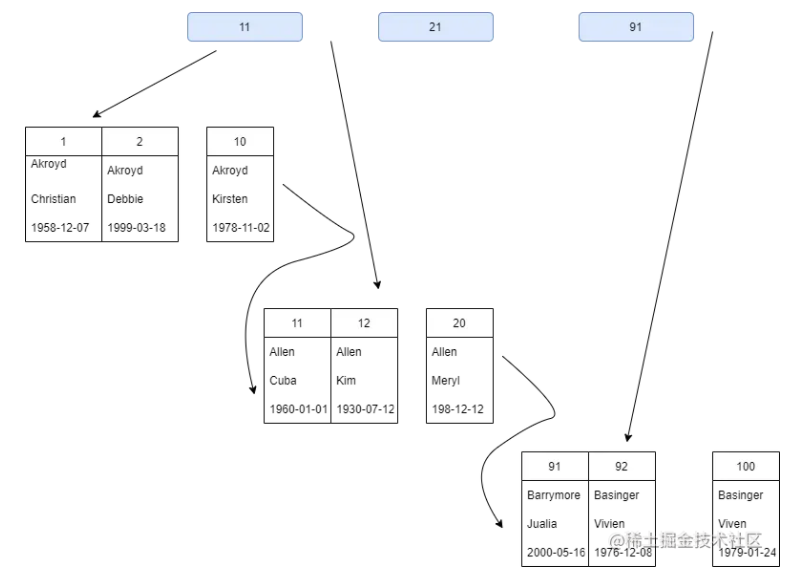
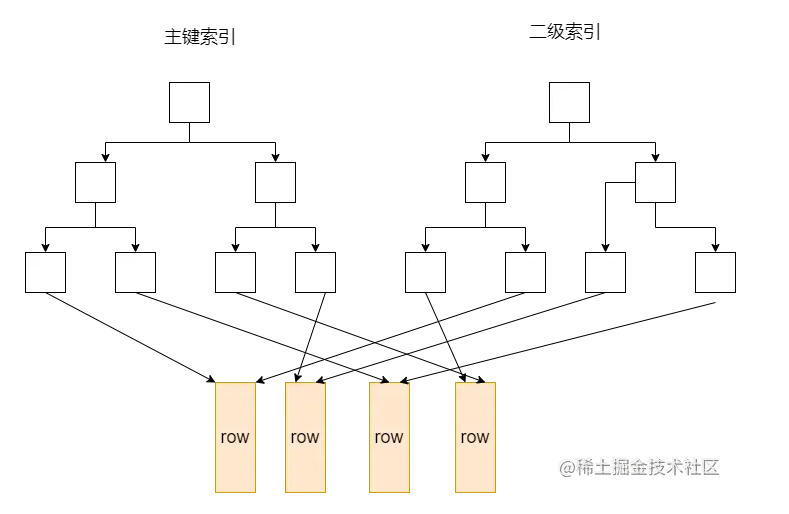
在聚簇索引中,除了主键索引,还有二级索引。二级索引中的叶子节点存储的不是“行指针”,而是主键值,并以此作为指向行的“指针”。这意味着通过二级索引查找行,存储引擎需要找到二级索引的叶子节点获得对应的主键值,然后根据这个值去聚簇索引中查找对应的行,也称为“回表”。当然,可以通过覆盖索引避免回表或者InnoDB的自适应索引能够减少这样的重复工作。
注意:聚簇索引中每一个叶子节点不止包含完整的数据行,还包括事务ID、用于事务和MVCC的回滚指针。
3.非聚簇索引
非聚簇索引的主键索引和二级索引在结构上没有什么不同,都在叶子节点上存储指向数据的物理地址的“行指针”。
聚簇索引的主键索引和二级索引:
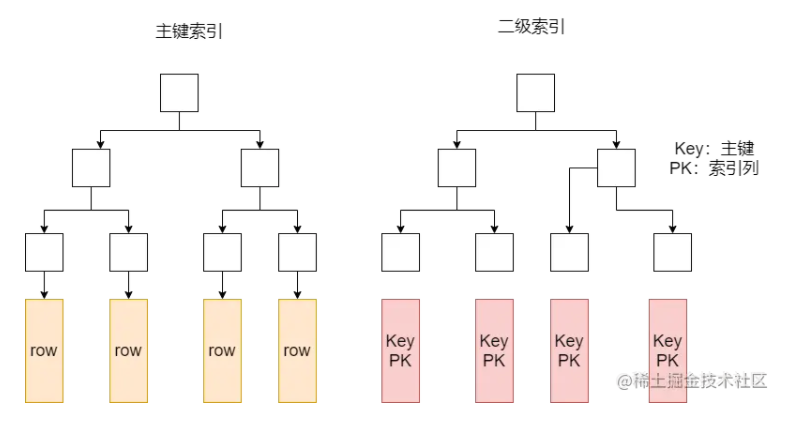
非聚簇索引的主键索引和二级索引:
4.聚簇索引的优缺点
优点:
把相关数据保存在一起(比如用用户ID把用户的全部邮件聚集在一起),否则每次数据读取就可能导致一次磁盘IO
数据访问更快,把索引和数据保存在同一个B+树中,通常在聚簇索引中获取数据比在非聚簇索引中查找更快
使用覆盖查询可以直接利用页节点中的主键值
缺点:
如果所有数据都可以放在内存中,顺序访问不再那么必要,聚簇索引没有优势
插入速度依赖于插入顺序,随机插入会导致页分裂,造成空洞,使用OPTIMIZE TABLE重建表
每次插入、更新、删除都需要维护索引的变化,代价很高
二级索引可能比想象中大,因为在节点中包含了引用行的主键列
5.哈希索引
哈希索引基于哈希表实现,只有精确匹配索引所有列的查询才有效,这意味着,哈希索引适用于等值查询。
具体实现:对于每一行数据,存储引擎都会对所有的索引列计算一个哈希码,哈希索引将所有的哈希码存储在索引中,同时在哈希表中保存指向每个数据行的指针。
在MySQL中,只有Memory引擎显式支持哈希索引,当然Memory引擎也支持B树索引。
注意:Memory引擎支持非唯一哈希索引,解决冲突的方式是以链表的形式存放多个哈希值相同的记录指针。
6.自适应哈希索引
InnoDB注意到某些索引值被使用得非常频繁时,会在内存中基于B+树索引之上再创建一个哈希索引,这样就让B+树索引也具有哈希索引的一些优点,比如快速的哈希查找。
到此这篇关于MySQL索引底层数据结构详情的文章就介绍到这了,更多相关MySQL索引底层数据结构内容请搜索NICE源码以前的文章或继续浏览下面的相关文章希望大家以后多多支持NICE源码!









