目录
- 1.如何定位并优化慢查询sql
- a.根据慢日志定位慢查询sql
- b.使用explain等工具分析sql
- c.修改sql或者尽量让sql走索引
- 2.联合索引的最左匹配原则的成因
- 简单说下什么是最左匹配原则
- 最左匹配原则的原理
- 3.索引是建立得越多越好吗
- 总结
1.如何定位并优化慢查询sql
a.根据慢日志定位慢查询sql
SHOW VARIABLES LIKE '%query%' 查询慢日志相关信息
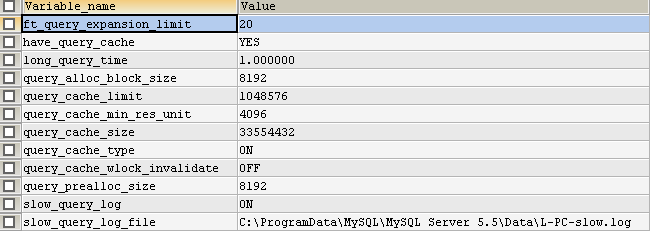
slow_query_log 默认是off关闭的,使用时,需要改为on 打开
slow_query_log_file 记录的是慢日志的记录文件
long_query_time 默认是10S,每次执行的sql达到这个时长,就会被记录
SHOW STATUS LIKE '%slow_queries%' 查看慢查询状态
![]()
Slow_queries 记录的是慢查询数量 当有一条sql执行一次比较慢时,这个vlue就是1 (记录的是本次会话的慢sql条数)
注意:
如何打开慢查询 : SET GLOBAL slow_query_log = ON;
将默认时间改为1S: SET GLOBAL long_query_time = 1;
(设置完需要重新连接数据库,PS:仅在这里改的话,当再次重启数据库服务时,所有设置又会自动恢复成默认值,永久改变需去my.ini中改)
b.使用explain等工具分析sql
在要执行的sql前加上explain 例如:EXPLAIN SELECT menu_name FROM t_sys_menu ORDER BY menu_id DESC;
![]()
接着看explain的关键字段
type:

如果发现type的值是最后两个中的其中一个时,证明语句需要优化了。
extra:

c.修改sql或者尽量让sql走索引
mysql查询优化器会根据具体情况自己判断走哪个索引,不一定是走主键(explain中的key可以看到走的哪个key)具体情况根据具体情况来定,当你要强制执行走某一个key时:
在查询的最后加上 force index(primary); 强制走主键的
2.联合索引的最左匹配原则的成因
简单说下什么是最左匹配原则
顾名思义:最左优先,以最左边的为起点任何连续的索引都能匹配上。同时遇到范围查询(>、<、between、like)就会停止匹配。
例如:b = 2 如果建立(a,b)顺序的索引,是匹配不到(a,b)索引的;但是如果查询条件是a = 1 and b = 2或者a=1(又或者是b = 2 and b = 1)就可以,因为优化器会自动调整a,b的顺序。再比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,因为c字段是一个范围查询,它之后的字段会停止匹配。
最左匹配原则的原理
最左匹配原则都是针对联合索引来说的,所以我们有必要了解一下联合索引的原理。了解了联合索引,那么为什么会有最左匹配原则这种说法也就理解了。
我们都知道索引的底层是一颗B+树,那么联合索引当然还是一颗B+树,只不过联合索引的健值数量不是一个,而是多个。构建一颗B+树只能根据一个值来构建,因此数据库依据联合索引最左的字段来构建B+树。
例子:假如创建一个(a,b)的联合索引,那么它的索引树是这样的
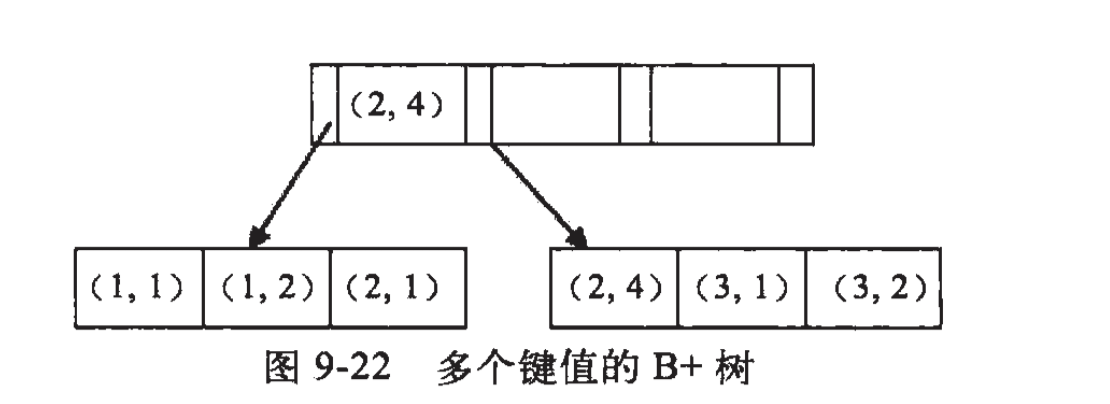
可以看到a的值是有顺序的,1,1,2,2,3,3,而b的值是没有顺序的1,2,1,4,1,2。所以b = 2这种查询条件没有办法利用索引,因为联合索引首先是按a排序的,b是无序的。
同时我们还可以发现在a值相等的情况下,b值又是按顺序排列的,但是这种顺序是相对的。所以最左匹配原则遇上范围查询就会停止,剩下的字段都无法使用索引。例如a = 1 and b = 2 a,b字段都可以使用索引,因为在a值确定的情况下b是相对有序的,而a>1and b=2,a字段可以匹配上索引,但b值不可以,因为a的值是一个范围,在这个范围中b是无序的。

成因:
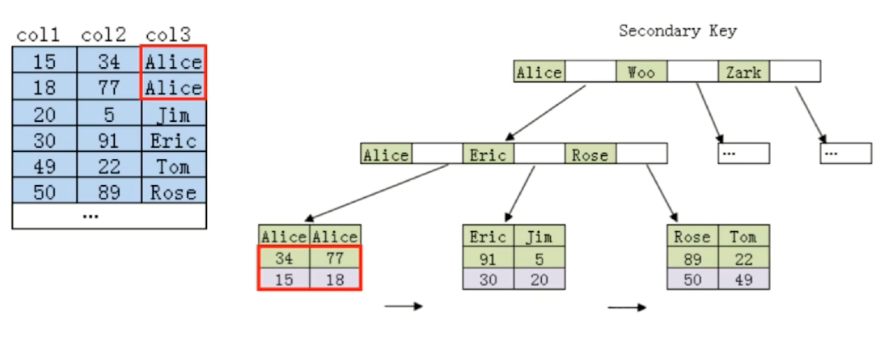
当通过(col3,col2)这样的联合索引去查找时,可以看到也是一个B+树的结构向下查找,若直接通过col2去查找,无法直接查找到34、77。也就用不到这个联合索引了。
3.索引是建立得越多越好吗
1.数据量小的表不需要建立索引,建立会增加额外的索引开销。
2.数据变更需要维护索引,因此更多的索引意味着更多的维护成本。
3.更多的索引意味着也需要更多的空间。
总结
到此这篇关于MySQL定位并优化慢查询sql的文章就介绍到这了,更多相关MySQL定位优化慢查询sql内容请搜索NICE源码以前的文章或继续浏览下面的相关文章希望大家以后多多支持NICE源码!









