目录
- 1.union:可以将查询结果相加
- 1)union all:不能去重
- 2)union:可以达到去重的效果。
- 2.limit:分页查询全靠它
- 1)对limit用法的一些说明
- 2)案例说明
- 3)通用的标准分页SQL
- 3.exists用法:又称”相关子查询”
- 1)带你理解exists的执行原理
- 2)案例演示
- 3)一张图说明exists子查询的原理
1.union:可以将查询结果相加
union用于将查询结果相加,尤其是将两张毫无关系的表中的数据,拼接在一起显示的时候。
但是有一个前提条件:不同结果进行拼接的时候,列数必须相同。
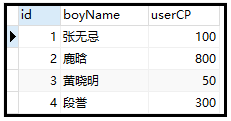
利用下方的数据说明union的用法:
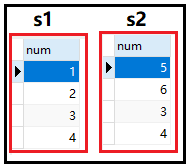
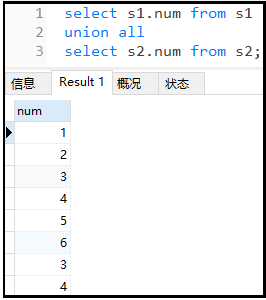
1)union all:不能去重
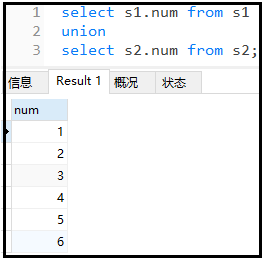
2)union:可以达到去重的效果。
2.limit:分页查询全靠它
1)对limit用法的一些说明
① limit是MySQL中特有的,其他数据库中没有,不通用;
② limit取结果集中的部分数据,这是它的作用;
③ limit是sql语句最后执行的一个环节;
limit的使用语法:
limit startIndex,length; 其中startIndex表示起始位置,从0开始,0表示第一条数据,length表示取几个。
2)案例说明
数据源如下:
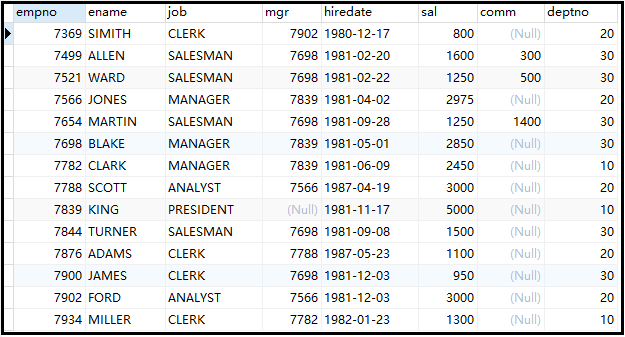
① 取出工资前五名的员工,显示其信息。
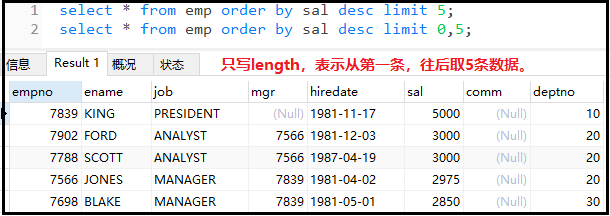
②找出工资排名在第4到第9名的员工。
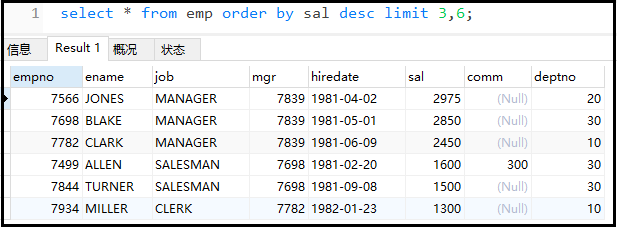
3)通用的标准分页SQL
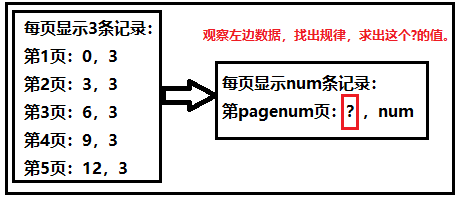
根据上图可以发现:
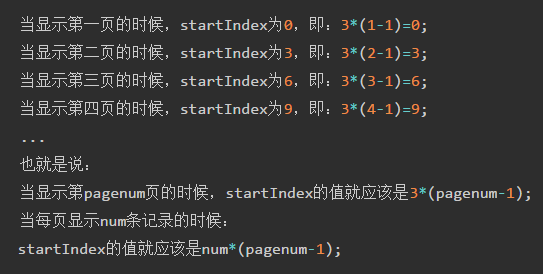
拿百度浏览器进行说明:

3.exists用法:又称”相关子查询”

1)带你理解exists的执行原理
数据源如下:
① 当返回结果是一行记录的情况
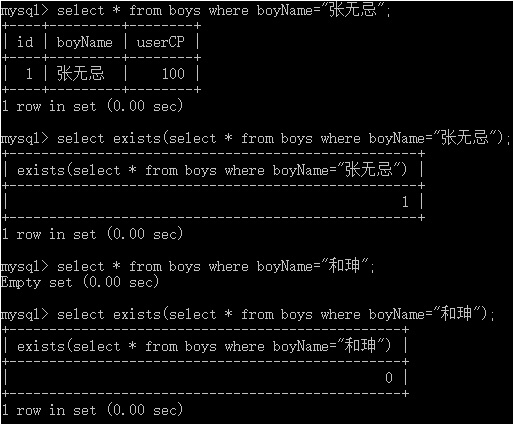
② 当返回结果是多行记录的情况
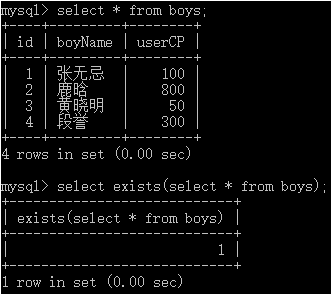
③ 原理解释
从上图演示可以发现,不管exists关键字后面的SQL语句,不管是查询出一条结果,还是多条结果,只要查出结果,整个结果就是True,而MySQL中True就用1表示,所以最终结果就是1。一旦exists关键字后面的SQL语句,查询不出任何一条结果的时候,最终的返回值就是False,在MySQL中False就用0表示,所以最终结果就是0。
2)案例演示
利用下方的数据源,完成如下两个练习题。
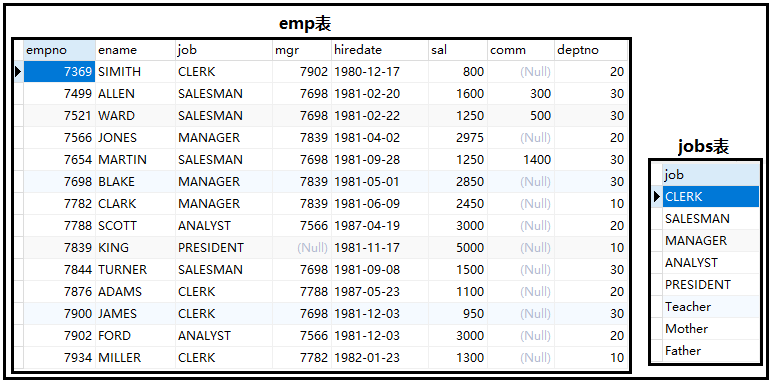
① 查询jobs表中,哪个工作有人做?
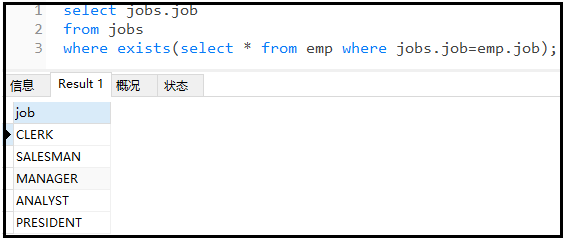
② 查询jobs表中,哪个工作没有人做?
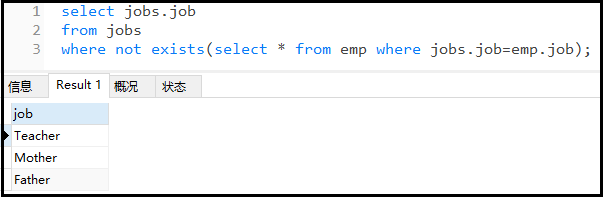
3)一张图说明exists子查询的原理
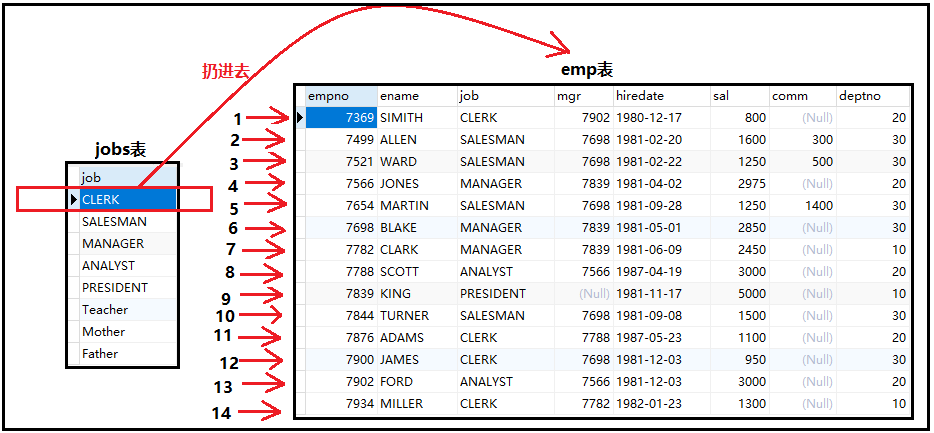
解释如下:
“有一个A公司,公司中所有的工作都在jobs表,emp表中可以看到哪些工作已经被做了”
select jobs.job
from jobs
where not exists(select * from emp where jobs.job=emp.job);
1)搞清楚你要得到的结果是什么。
这里你要得到的是”哪些工作没有人做”,也就是说返回的结果来自于jobs表,但是
“怎么知道哪些工作有人做,哪些没人做呢?”,这就需要我们对照emp表。
2)首先从jobs表中,取出第一条记录,扔进到emp表中和该表的每一行进行匹配。当匹
配到第一行的时候,由于emp表中的每一行都有8列,你究竟想匹配什么呢?是不是应该明
确指明以下,也就是”where jobs.job=emp.job”这个条件,这个条件表明,我从jobs
表中取出第一条记录,去和emp中每一行进行匹配,并且我更为明确,我是和你第一行的
job字段进行匹配,你只需要看看jobs.job和emp.job是否相等,如果相等,返回该条记
录,接着,拿着第一行再往下依次匹配,只要是jobs.job和emp.job是否相等,就返回
该条记录。因此jobs中的第一行和emp中每一行进行匹配,就会返回一个结果集。
3)再看exists关键字,exists()返回的结果是true或者false,当括号中有值的时候,
就是存在,返回的是true;当括号中没有值的时候,返回的是false。根据(1)中,我们
已经知道,jobs中的第一行和emp中每一行匹配后,返回了一个结果集,也就证明有返回
值,因此exists()返回的结果是true。
4)当在exists()前面加了一个not,表示取反。exists()返回的是true,not exists()
返回的就是false。
5)根据上述叙述,当not exists()变为false后,原始语句就相当于变为:
select jobs.job from jobs where false;
因此,第一行clerk不能被取出来。
6)接着,再拿jobs中的第二行”SALESMAN”,去和emp表中的每一行进行一一匹配,依然重
复上述步骤。
以上就是MySQL系列一文读懂union(all)与limit及exists关键字教程的详细内容,更多关于MySQL系列union(all)与limit及exists关键字的资料请关注NICE源码其它相关文章!








