目录
- 一、V8来源
- 二、V8的服务对象
- 三、V8的早期架构
- 四、V8早期架构的缺陷
- 五、V8的现有架构
- 六、V8的词法分析和语法分析
- 七、V8 AST抽象语法树
- 八、字节码
- 九、Turbofan
一、V8来源
V8的名字来源于汽车的“V型8缸发动机”(V8发动机)。V8发动机主要是美国发展起来,因为马力十足而广为人知。V8引擎的命名是Google向用户展示它是一款强力并且高速的JavaScript引擎。
V8未诞生之前,早期主流的JavaScript引擎是JavaScriptCore引擎。JavaScriptCore是主要服务于Webkit浏览器内核,他们都是由苹果公司开发并开源出来。据说Google是不满意JavaScriptCore和Webkit的开发速度和运行速度,Google另起炉灶开发全新的JavaScript引擎和浏览器内核引擎,所以诞生了V8和Chromium两大引擎,到现在已经是最受欢迎的浏览器相关软件。
二、V8的服务对象
V8是依托Chrome发展起来的,后面确不局限于浏览器内核。发展至今V8应用于很多场景,例如流行的nodejs,weex,快应用,早期的RN。
三、V8的早期架构
V8引擎的诞生带着使命而来,就是要在速度和内存回收上进行革命的。JavaScriptCore的架构是采用生成字节码的方式,然后执行字节码。Google觉得JavaScriptCore这套架构不行,生成字节码会浪费时间,不如直接生成机器码快。所以V8在前期的架构设计上是非常激进的,采用了直接编译成机器码的方式。后期的实践证明Google的这套架构速度是有改善,但是同时也造成了内存消耗问题。可以看下V8的初期流程图:
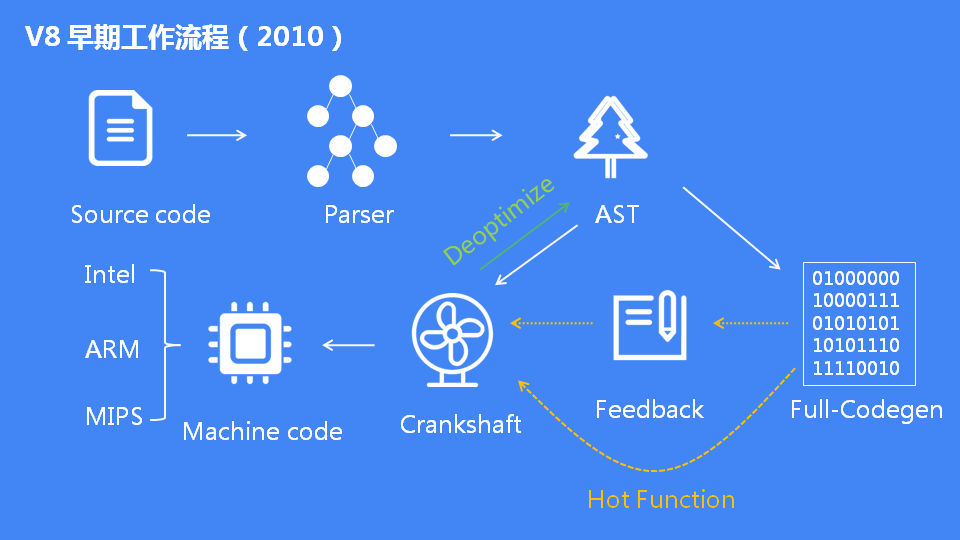
早期的V8有Full-Codegen和Crankshaft两个编译器。V8 首先用 Full-Codegen把所有的代码都编译一次,生成对应的机器码。JS在执行的过程中,V8内置的Profiler筛选出热点函数并且记录参数的反馈类型,然后交给 Crankshaft 来进行优化。所以Full-Codegen本质上是生成的是未优化的机器码,而Crankshaft生成的是优化过的机器码。
四、V8早期架构的缺陷
随着版本的引进,网页的复杂化,V8也渐渐的暴露出了自己架构上的缺陷:
- Full-Codegen编译直接生成机器码,导致内存占用大
- Full-Codegen编译直接生成机器码,导致编译时间长,导致启动速度慢
- Crankshaft 无法优化try,catch和finally等关键字划分的代码块
- Crankshaft新加语法支持,需要为此编写适配不同的Cpu架构代码
五、V8的现有架构
为了解决上述缺点,V8采用JavaScriptCore的架构,生成字节码。这里是不是感觉Google又绕回来了。V8采用生成字节码的方式,整体流程如下图:
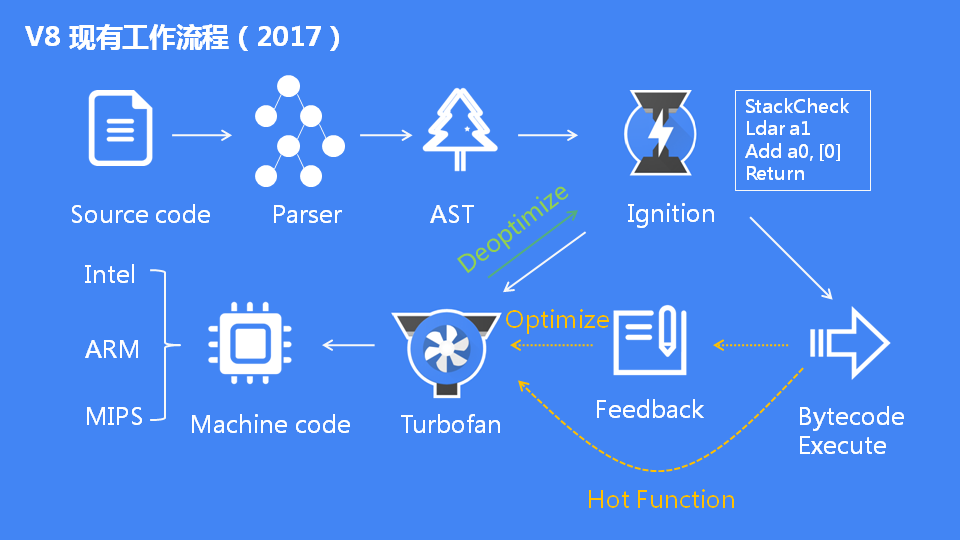
Ignition是V8的解释器,背后的原始动机是减少移动设备上的内存消耗。在Ignition之前,V8的Full-codegen基线编译器生成的代码通常占据Chrome整体JavaScript堆的近三分之一。这为Web应用程序的实际数据留下了更少的空间。
Ignition的字节码可以直接用TurboFan生成优化的机器代码,而不必像Crankshaft那样从源代码重新编译。Ignition的字节码在V8中提供了更清晰且更不容易出错的基线执行模型,简化了去优化机制,这是V8 自适应优化的关键特性。最后,由于生成字节码比生成Full-codegen的基线编译代码更快,因此激活Ignition通常会改善脚本启动时间,从而改善网页加载。
TurboFan是V8的优化编译器,TurboFan项目最初于2013年底启动,旨在解决Crankshaft的缺点。Crankshaft只能优化JavaScript语言的子集。例如,它不是设计用于使用结构化异常处理优化JavaScript代码,即由JavaScript的try,catch和finally关键字划分的代码块。很难在Crankshaft中添加对新语言功能的支持,因为这些功能几乎总是需要为九个支持的平台编写特定于体系结构的代码。
采用新架构后的优势
不同架构下V8的内存对比,如图:
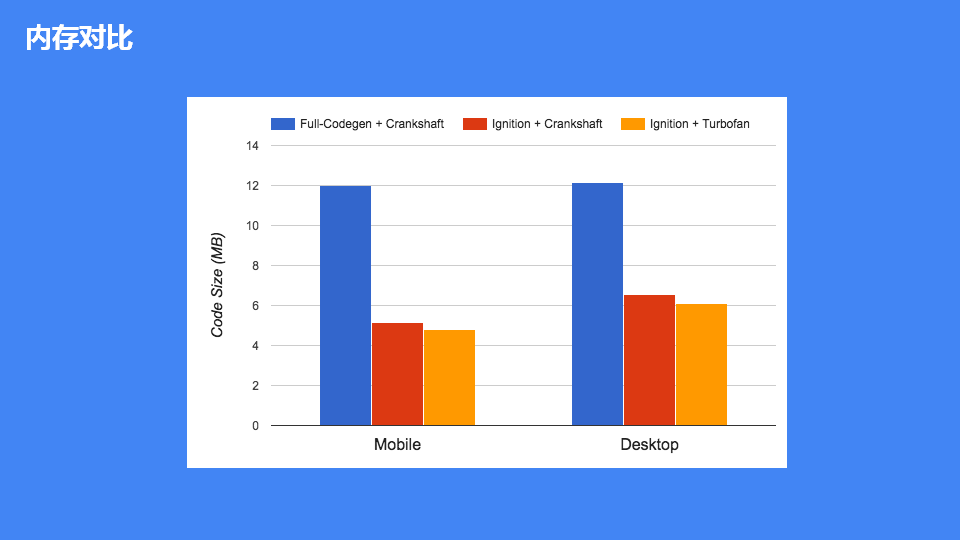
结论:可以明显看出Ignition+TurboFan架构比Full-codegen+Crankshaft架构内存降低一半多。
不同架构网页速度提升对比,如图:
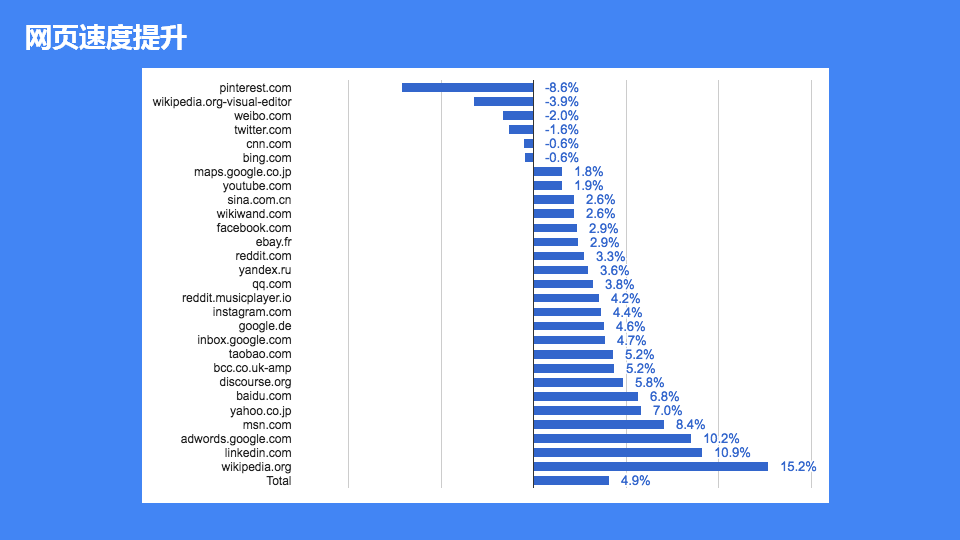
结论:可以明显看出Ignition+TurboFan架构比Full-codegen+Crankshaft架构70%网页速度是有提升的。
接下来我们大致的讲解下现有架构的每个流程:
六、V8的词法分析和语法分析
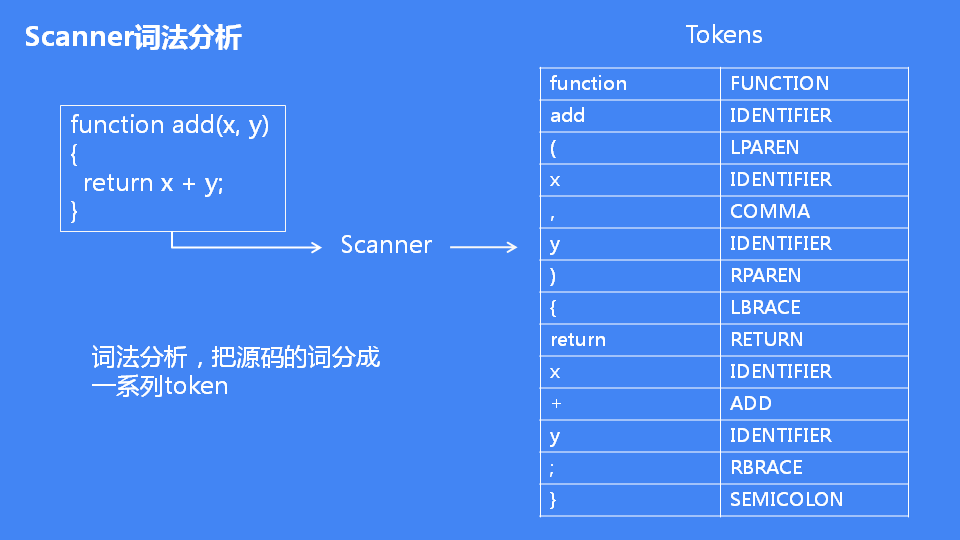
学过编译原理的同学可以知道,JS文件只是一个源码,机器是无法执行的,词法分析就是把源码的字符串分割出来,生成一系列的token,如下图可知不同的字符串对应不同的token类型。
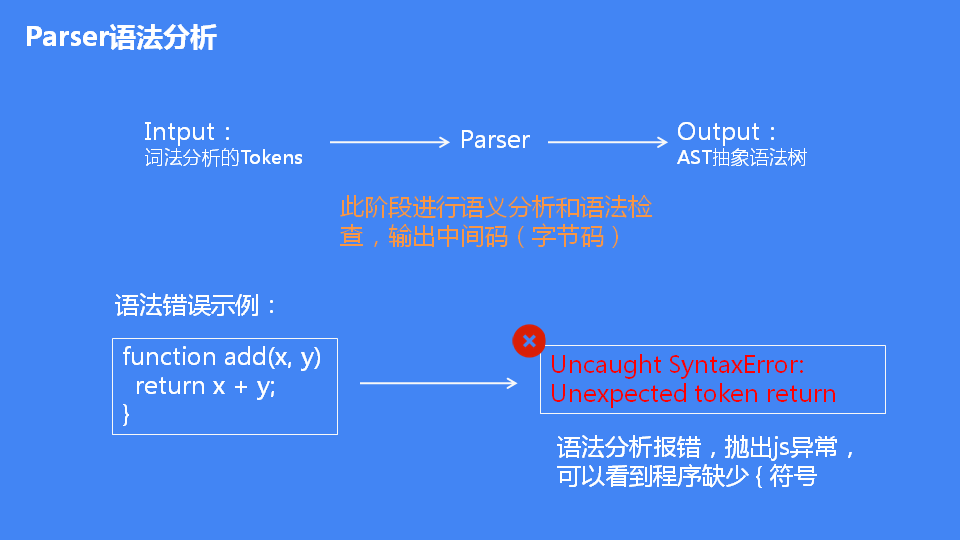
词法分析完后,接下来的阶段就是进行语法分析。语法分析语法分析的输入就是词法分析的输出,输出是AST抽象语法树。当程序出现语法错误的时候,V8在语法分析阶段抛出异常。
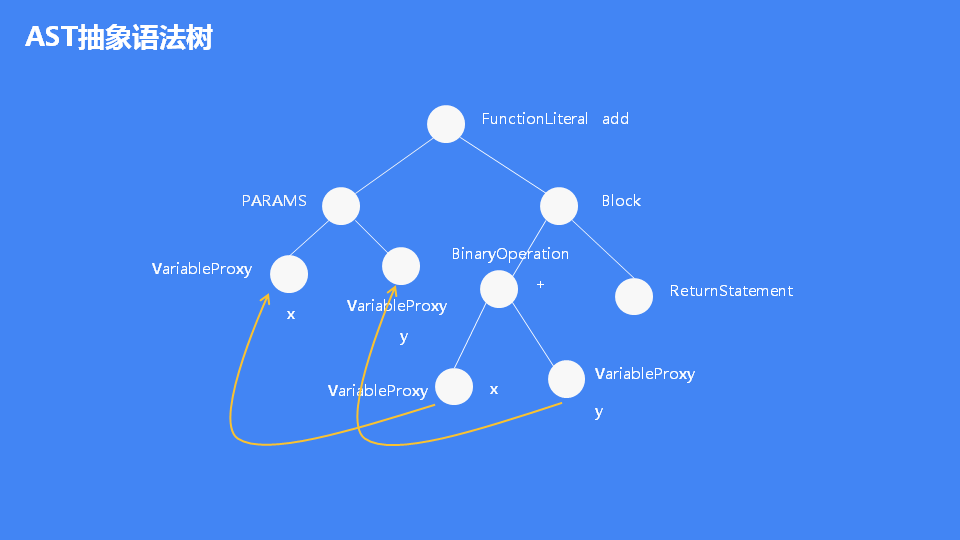
七、V8 AST抽象语法树
下图是一个add函数的抽象语法树数据结构
V8 Parse阶段后,接下来就是根据抽象语法树生成字节码。如下图可以看出add函数生成对应的字节码:
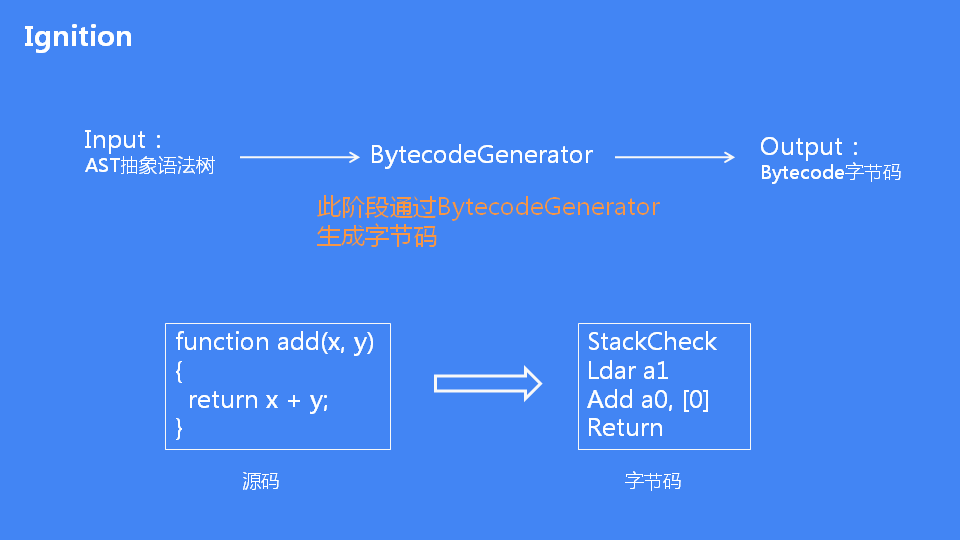
BytecodeGenerator类的作用是根据抽象语法树生成对应的字节码,不同的node会对应一个字节码生成函数,函数开头为Visit****。如下图+号对应的函数字节码生成:

void BytecodeGenerator::VisitArithmeticExpression(BinaryOperation* expr) {
FeedbackSlot slot = feedback_spec()->AddBinaryOpICSlot();
Expression* subexpr;
Smi* literal;
if (expr->IsSmiLiteralOperation(&subexpr, &literal)) {
VisitForAccumulatorValue(subexpr);
builder()->SetExpressionPosition(expr);
builder()->BinaryOperationSmiLiteral(expr->op(), literal,
feedback_index(slot));
} else {
Register lhs = VisitForRegisterValue(expr->left());
VisitForAccumulatorValue(expr->right());
builder()->SetExpressionPosition(expr); // 保存源码位置 用于调试
builder()->BinaryOperation(expr->op(), lhs, feedback_index(slot)); // 生成Add字节码
}
}
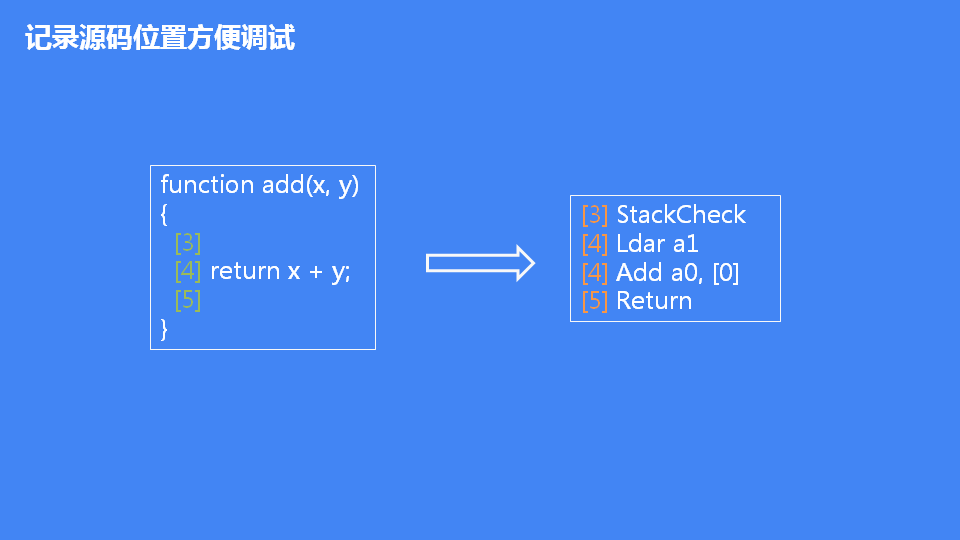
上述可知有个源码位置记录,然后下图可知源码和字节码位置的对应关系:
生成字节码,那字节码如何执行的呢?接下来讲解下:
八、字节码
首先说下V8字节码:
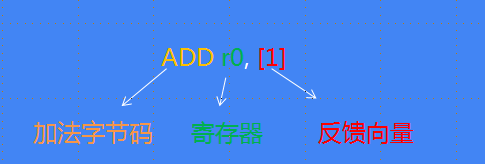
每个字节码指定其输入和输出作为寄存器操作数
Ignition 使用registers寄存器 r0,r1,r2… 和累加器寄存器(accumulator register)
registers寄存器:函数参数和局部变量保存在用户可见的寄存器中
累加器:是非用户可见寄存器,用于保存中间结果
如下图ADD字节码:
字节码执行
下面一系列图表示每个字节码执行时,对应寄存器和累加器的变化,add函数传入10,20的参数,最终累加器返回的结果是50。








每个字节码对应一个处理函数,字节码处理程序保存的地址在dispatch_table_中。执行字节码时会调用到对应的字节码处理程序进行执行。Interpreter类成员dispatch_table_保存了每个字节码的处理程序地址。

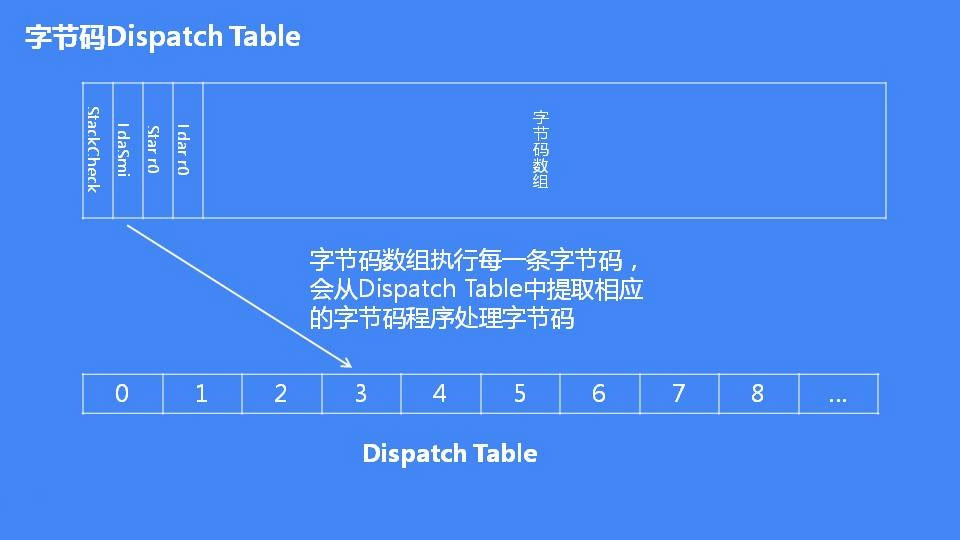
例如ADD字节码对应的处理函数是(当执行ADD字节码时候,会调用InterpreterBinaryOpAssembler类):
IGNITION_HANDLER(Add, InterpreterBinaryOpAssembler) {
BinaryOpWithFeedback(&BinaryOpAssembler::Generate_AddWithFeedback);
}
void BinaryOpWithFeedback(BinaryOpGenerator generator) {
Node* reg_index = BytecodeOperandReg(0);
Node* lhs = LoadRegister(reg_index);
Node* rhs = GetAccumulator();
Node* context = GetContext();
Node* slot_index = BytecodeOperandIdx(1);
Node* feedback_vector = LoadFeedbackVector();
BinaryOpAssembler binop_asm(state());
Node* result = (binop_asm.*generator)(context, lhs, rhs, slot_index,
feedback_vector, false);
SetAccumulator(result); // 将ADD计算的结果设置到累加器中
Dispatch(); // 处理下一条字节码
}
其实到此JS代码就已经执行完成了。在执行过程中,发现有热点函数,V8会启用Turbofan进行优化编译,直接生成机器码,所以接下来讲解下Turbofan优化编译器:
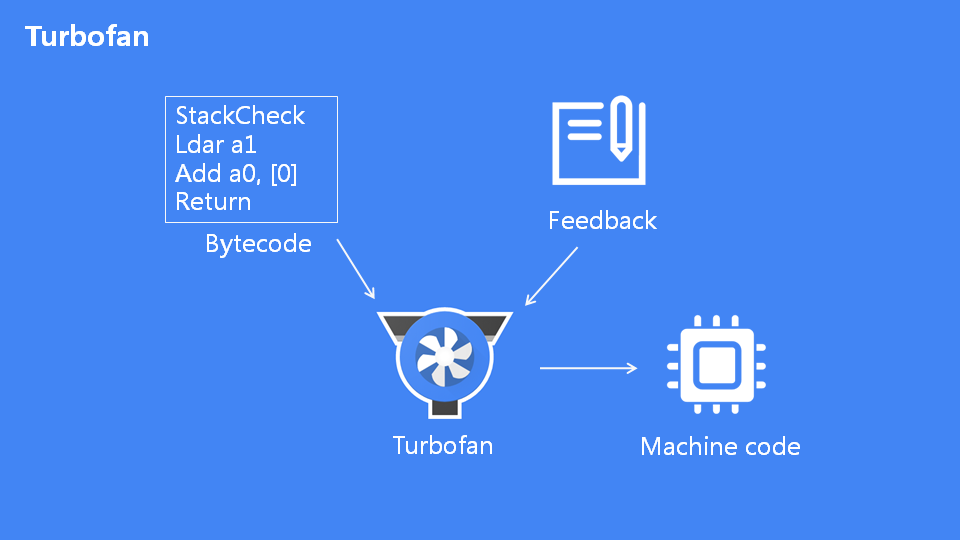
九、Turbofan
Turbofan是根据字节码和热点函数反馈类型生成优化后的机器码,Turbofan很多优化过程,基本和编译原理的后端优化差不多,采用的sea-of-node。
add函数优化:
function add(x, y) {
return x+y;
}
add(1, 2);
%OptimizeFunctionOnNextCall(add);
add(1, 2);
V8是有函数可以直接调用指定优化哪个函数,执行%OptimizeFunctionOnNextCall主动调用Turbofan优化add函数,根据上次调用的参数反馈优化add函数,很明显这次的反馈是整型数,所以turbofan会根据参数是整型数进行优化直接生成机器码,下次函数调用直接调用优化好的机器码。(注意执行V8需要加上 –allow-natives-syntax,OptimizeFunctionOnNextCall为内置函数,只有加上 –allow-natives-syntax,JS才能调用内置函数 ,否则执行会报错)。
JS的add函数生成对应的机器码如下:

这里会涉及small interger小整数概念,可以查看这篇文章https://zhuanlan.zhihu.com/p/82854566
如果把add函数的传入参数改成字符
function add(x, y) {
return x+y;
}
add(1, 2);
%OptimizeFunctionOnNextCall(add);
add(1, 2);
优化后的add函数生成对应的机器码如下:

对比上面两图,add函数传入不同的参数,经过优化生成不同的机器码。
如果传入的是整型,则本质上是直接调用add汇编指令
如果传入的是字符串,则本质上是调用V8的内置Add函数
到此V8的整体执行流程就结束了。
以上就是详解JavaScript引擎V8执行流程的详细内容,更多关于JavaScript引擎V8的资料请关注NICE源码其它相关文章!