目录
- 一、装不进冰箱的大象
- 二、影分身的字符串
- 三、如朕亲临的 ‘奇球’
- 四、扑朔迷离的数字
- 五、小结:基本类型到底存在哪里?
JavaScript中基本类型存储在堆中还是栈中?
—- 不基本类型的基本类型
看到这个问题,相信大家都觉得这个题目实在基础的不能再基础了。随手百度一下,就能看到很多人说:基本类型存在栈中,引用类型存在堆中。
真的这么简单么?
一、装不进冰箱的大象
让我们看一下这段代码:
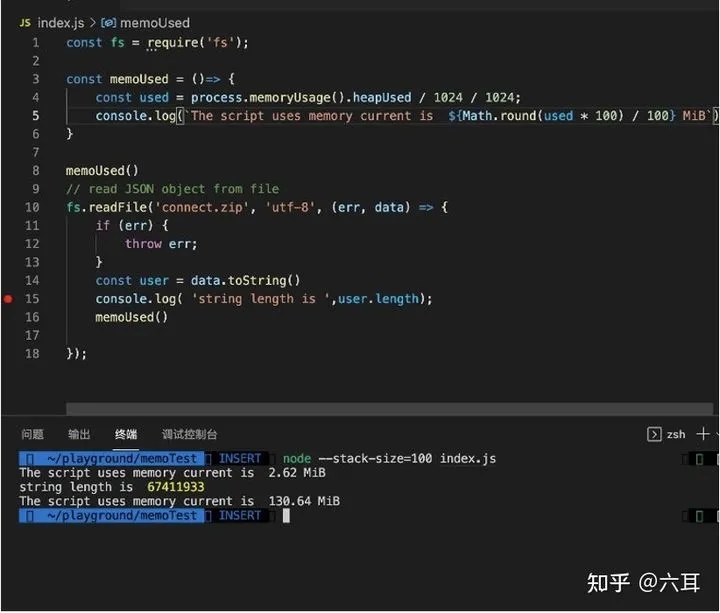
在这里,我们声明了一个67MiB大小的字符串,如果字符串真的存在栈中,这就不好解释了。毕竟,v8默认的栈区大小为984KiB。肯定是存不下的。
注:在不同时期,不同操作系统中V8对于字符串大小的限制并不相同。大概有个范围是256MiB ~ 1GiB
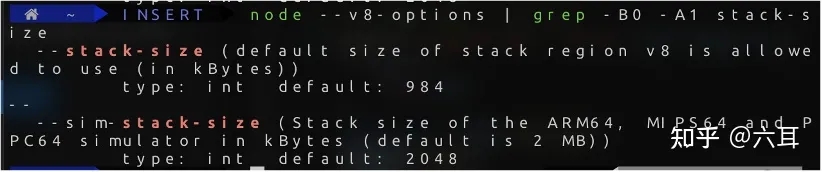
node --v8-options | grep -B0 -A1 stack-size
说到这里,各位是不是心里已经开始疑惑了呢。难道百度的答案不对,得用谷歌搜?
让我们看看这到底是怎么回事。
二、影分身的字符串
const BasicVarGen = function () {
this.s1 = 'IAmString'
this.s2 = 'IAmString'
}
let a = new BasicVarGen()
let b = new BasicVarGen()
在这里,我们声明了两个一样的对象,每个对象包括两个相同的字符串。
通过开发者工具,我们看到虽然我们声明了四个字符串,但是其内存指向了同一个地址。
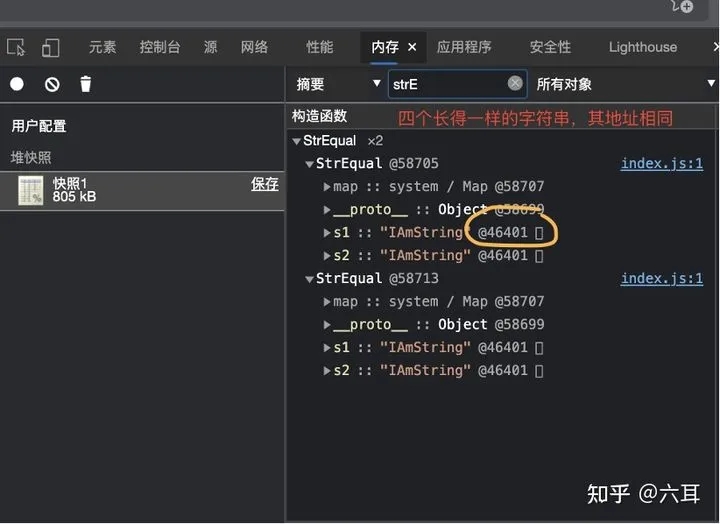
备注:chrome无法查看实际地址,此处为抽象后的地址
这说明了啥?说明了四个字符串中存的是引用地址。
所以上文中那个无法装进冰箱的大象,也就好解释了。字符串并没有存到栈中,而是存到了一个别的地方,再把这个地方的地址存到了栈中。
那,让我们修改一下其中一个字符串的内容
const BasicVarGen = function () {
this.s0 = 'IAmString'
this.s1 = 'IAmString'
}
let a = new BasicVarGen()
let b = new BasicVarGen()
debugger
a.s0 = 'different string'
a.s2 = 'IAmString'
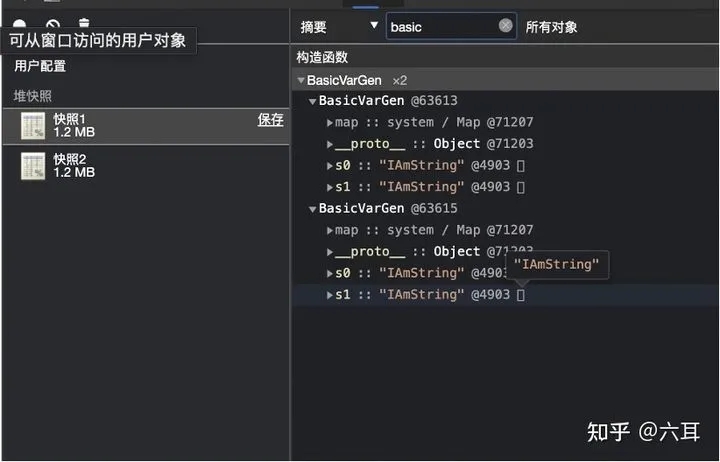
debugger之前的内存快照
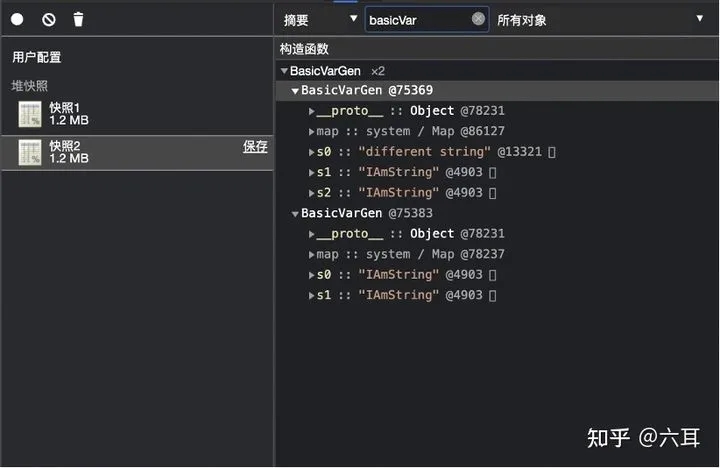
debugger之后的内存快照
我们可以看到,a.s0 一开始内容为 ‘IAmString' ,在我们修改其内容后,地址发生了变化。
而我们新增的a.s2 其内容为 ‘IAmString' ,其地址与其他值为 ‘IAmString' 的变量保持一致。
当我们声明一个字符串时:
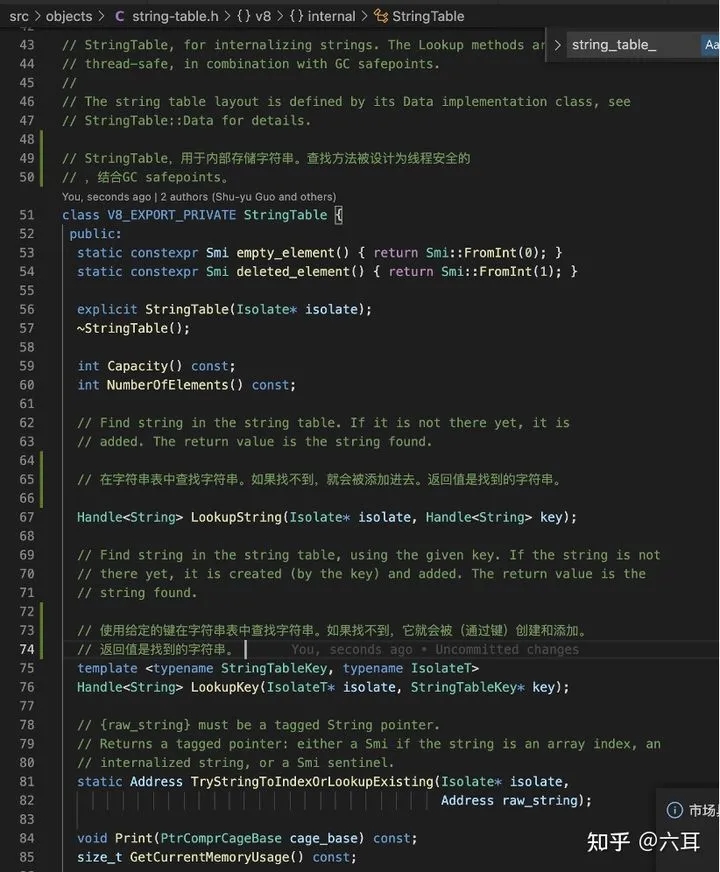
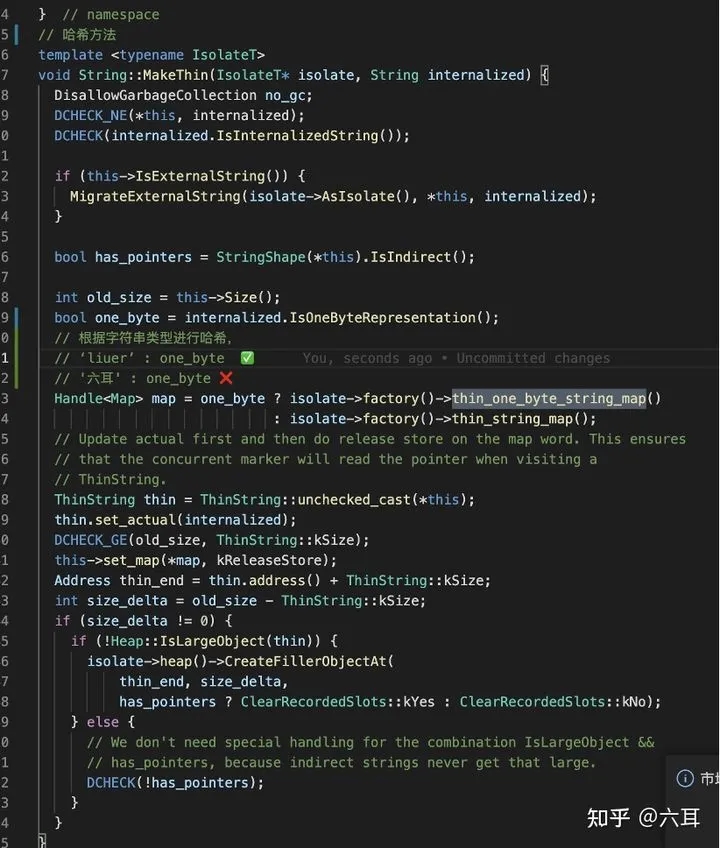
- v8内部有一个名为
stringTable的hashmap缓存了所有字符串,在V8阅读我们的代码,转换抽象语法树时,每遇到一个字符串,会根据其特征换算为一个hash值,插入到hashmap中。在之后如果遇到了hash值一致的字符串,会优先从里面取出来进行比对,一致的话就不会生成新字符串类。 - 缓存字符串时,根据字符串不同采取不同
hash方式。
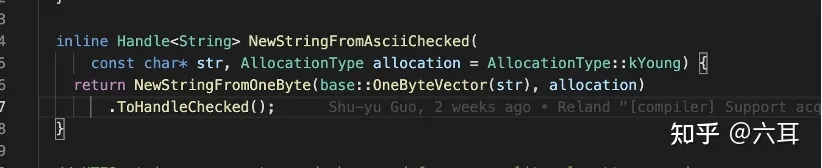
所以让我们梳理一下,在我们创建字符串的时候,V8会先从内存中(哈希表)查找是否有已经创建的完全一致的字符串,如果存在,直接复用。如果不存在,则开辟一块新的内存空间存进这个字符串,然后把地址赋到变量中。这也是为什么我们不能直接用下标的方式修改字符串: V8中的字符串都是不可变的。
拿出一个js的基本类型拷贝举例讲一下v8的实现逻辑和常规的大家理解的逻辑(雅文)
例:
var a = "刘潇洒"; // V8读取字符串后,去stringTable查找是否存在 不存在 hashTable 插入 '刘潇洒' 并把'刘潇洒'的引用存入 a var b = a; // 直接拷贝 '刘潇洒' 的引用 b = "谭雅文"; // 查找 无 存入stringTable
疑问点:
const BasicVarGen = function () {
this.s0 = 'IAmString'
this.s1 = 'IAmString'
}
let a = new BasicVarGen()
let b = new BasicVarGen()
debugger
a.s0 = 'different string'
a.s2 = 'IAmString'
a.s3 = a.s2+a.s0; // 疑问点: 字符串拼接做了哪些操作?
a.s4 = a.s2+a.s
同时申请两个拼接的字符串,内容相同。
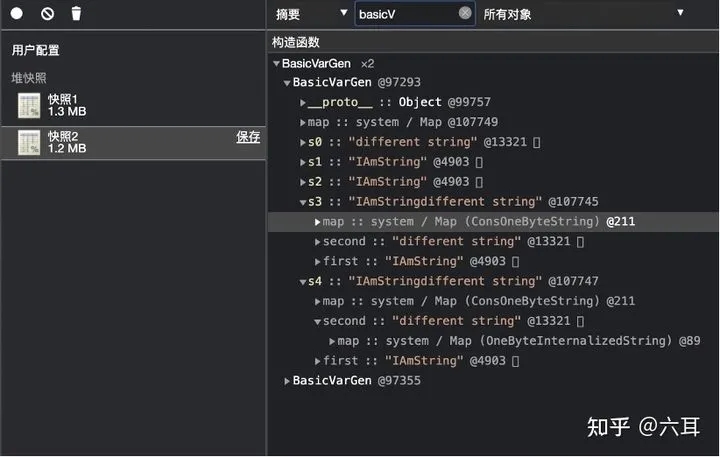
可以看到,虽然其内容相同。但是地址并不相同。而且,地址前方的Map描述也发生了变化。
字符串拼接时如果以传统方式(如
SeqString)存储,拼接操作的时间复杂度为 O(n) ,采用 绳索结构[Rope Structure] (也就是ConsString所采用的数据结构)可以减少拼接所花费的时间。
如果字符串是这样,那别的基本类型也是如此么?
三、如朕亲临的 ‘奇球’
说完字符串,让我们看看V8中另外一类典型的‘基本类型’:oddBall。
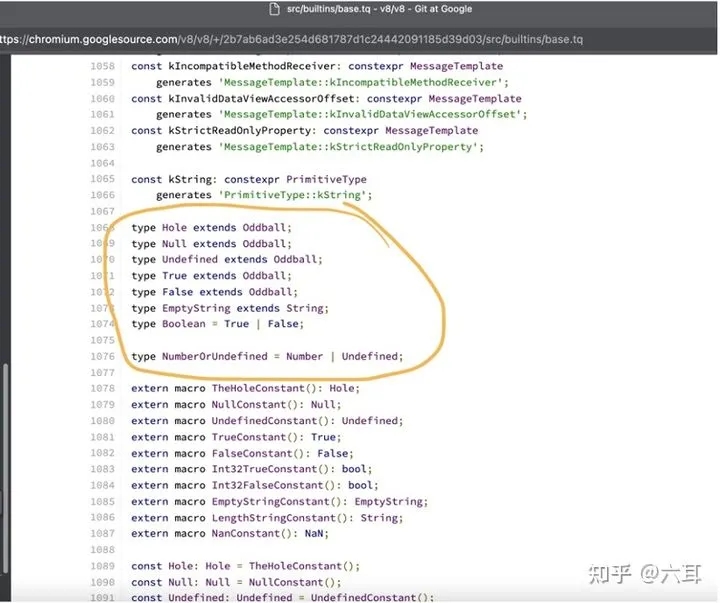
拓展自oddBall的type
让我们再做一个小实验:
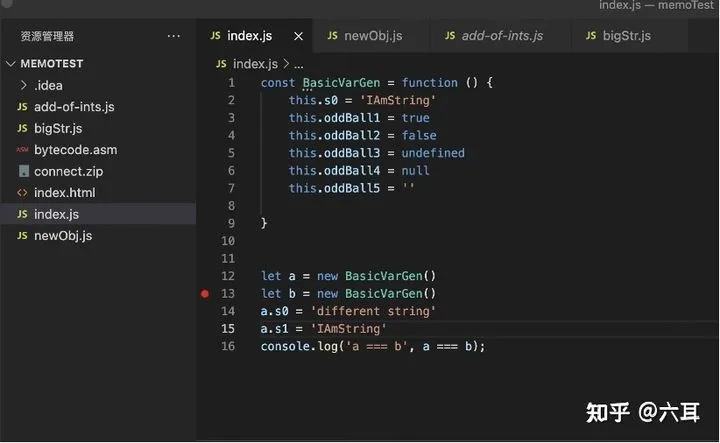
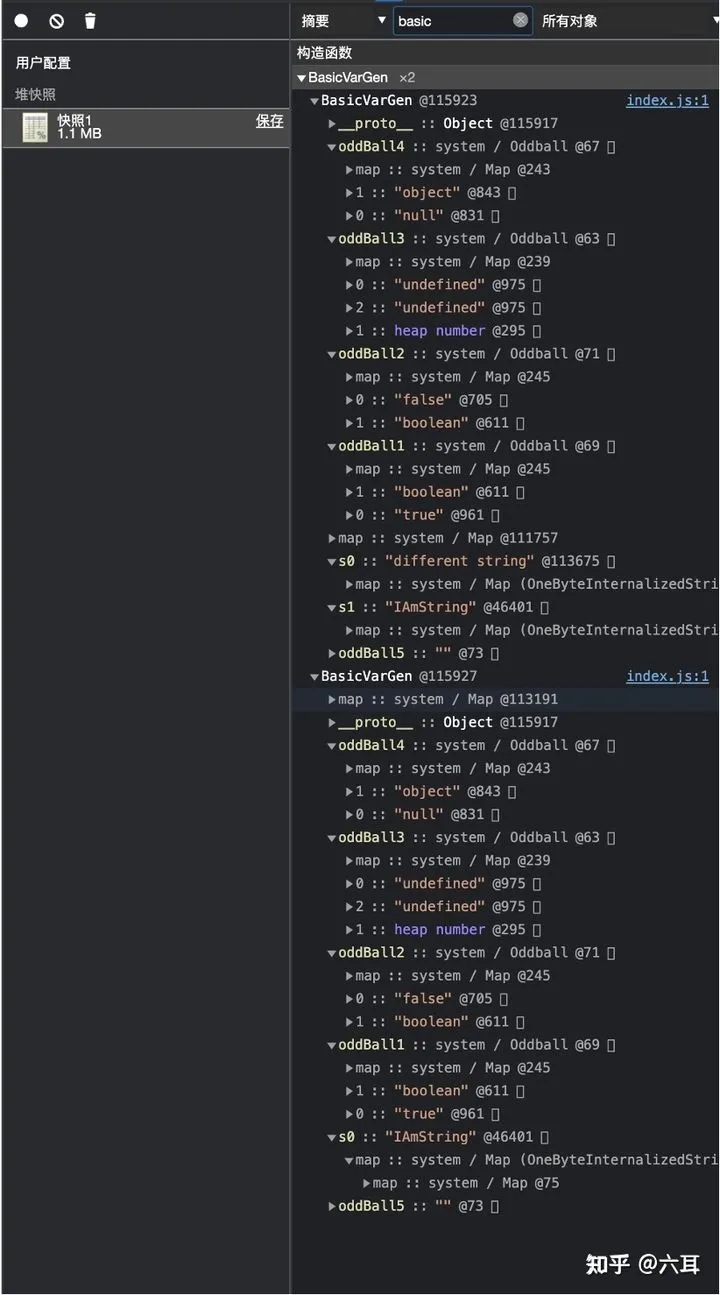
我们可以看到 上图中列举的基本类型,地址也是相同的。在赋值时,也是就地复用。(而且这些拓展自oddBall的基本类型,其地址是固定的,也就是说,在V8跑起来的第一时间,不管我们有没有声明这些基本类型,他们都已经被创建完毕了。而我们声明对象时,赋的是他们的引用。这也可以解释为什么我们说基本类型是赋到栈中:在V8中,存放在 @73 的值,永远是空字符串,那么v8就可以等效把这些地址视为值本身。)
让我们看看源码,验证一下:
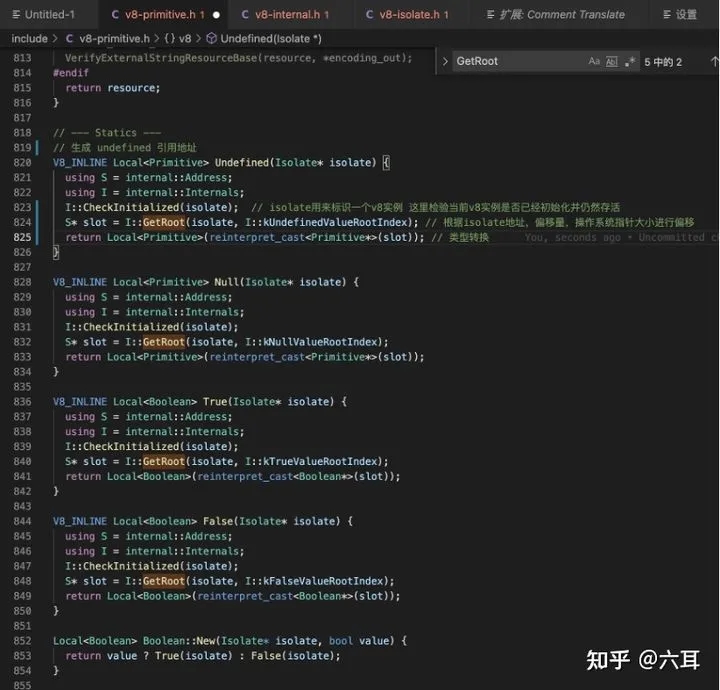
生成各种oddBall类型的方法,可以看出返回的是一个地址
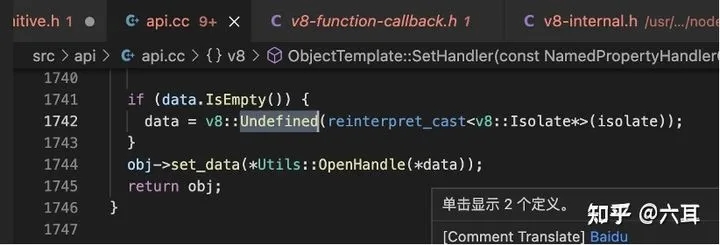
undefined赋值给一个变量,其实赋的是地址
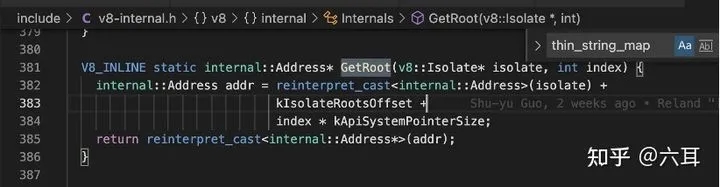
getRoot方法
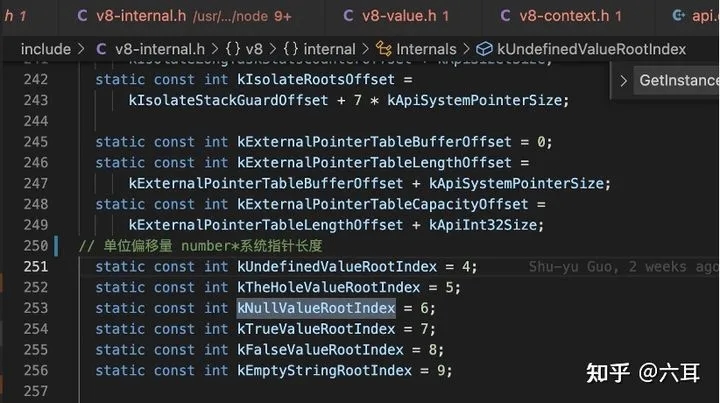
偏移量定义的地方
四、扑朔迷离的数字
之所以叫扑朔迷离的数字,是因为还没有搞明白其分配与改变时内存分配的机制。(其内存是动态的)
数字在V8中分为 smi 和 heapNumber。
smi 直接存进内存范围为 :-2³¹ 到 2³¹-1(2³¹≈2*10⁹)的整数
heapNumber 类似字符串 不可变范围为 :所有非smi的数字
最低位用来表示是否为指针 最低位为1 则是一个指针
const o = {
x: 42, // Smi
y: 4.2, // HeapNumber
};
o.x 中的 42 会被当成 Smi 直接存储在对象本身,而 o.y 中的 4.2 需要额外开辟一个内存实体存放,并将 o.y 的对象指针指向该内存实体。
如果是 32 位操作系统,用32位表示smi 可以理解,可是64位操作系统中,为什么 smi 范围也是 -2³¹ 到 2³¹-1(2³¹≈2*10⁹)?
ECMAScript 标准约定 number 数字需要被当成 64 位双精度浮点数处理,但事实上,一直使用 64 位去存储任何数字实际是非常低效的(空间低效,计算时间低效 smi大量使用位运算),所以 JavaScript 引擎并不总会使用 64 位去存储数字,引擎在内部可以采用其他内存表示方式(如 32 位),只要保证数字外部所有能被监测到的特性对齐 64 位的表现就行。
const cycleLimit = 50000
console.time('heapNumber')
const foo = { x: 1.1 };
for (let i = 0; i < cycleLimit; ++i) {
// 创建了多出来的heapNumber实例
foo.x += 1;
}
console.timeEnd('heapNumber') // slow
console.time('smi')
const bar = { x: 1.0 };
for (let i = 0; i < cycleLimit; ++i) {
bar.x += 1;
}
console.timeEnd('smi') // fast
疑问点:
const BasicVarGen = function () {
this.smi1 = 1
this.smi2 = 2
this.heapNumber1 = 1.1
this.heapNumber2 = 2.1
}
let foo = new BasicVarGen()
let bar = new BasicVarGen()
debugger
baz.obj1.heapNumber1 ++
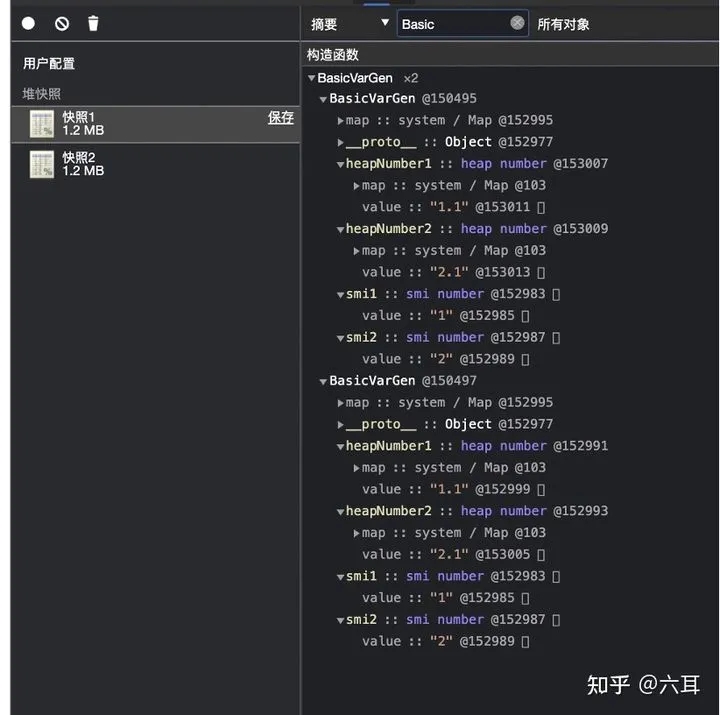
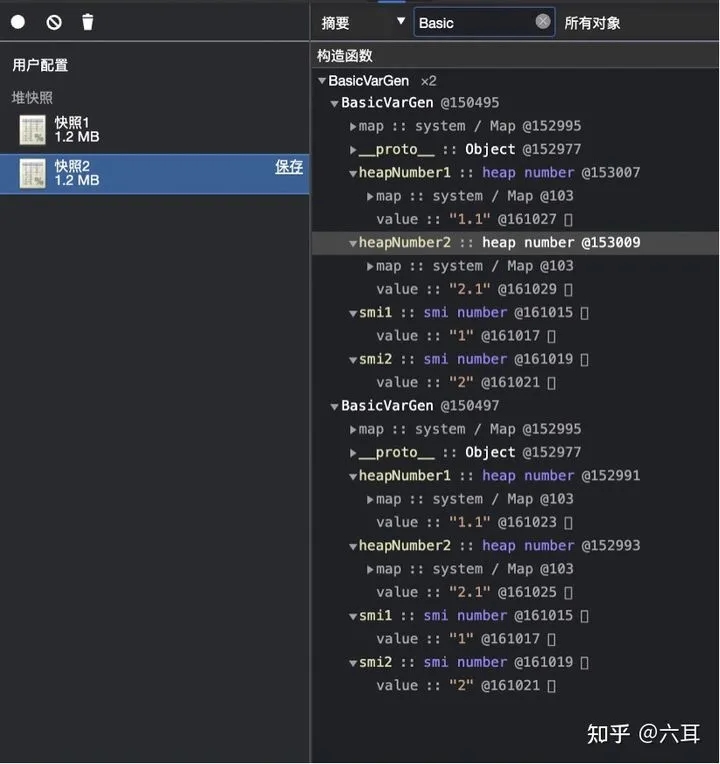
在数字中,一个数字的值都没有修改,其他的数字地址也都变了。
五、小结:基本类型到底存在哪里?
字符串: 存在堆里,栈中为引用地址,如果存在相同字符串,则引用地址相同。
数字: 小整数存在栈中,其他类型存在堆中。
其他类型:引擎初始化时分配唯一地址,栈中的变量存的是唯一的引用。
这里只能算是大概讲明白了基本类型存在哪里,
到此这篇关于深入内存原理谈JS中变量存储在堆中还是栈中的文章就介绍到这了,更多相关JS中变量存储在堆中还是栈中内容请搜索NICE源码以前的文章或继续浏览下面的相关文章希望大家以后多多支持NICE源码!