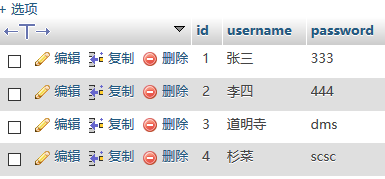
本文实例讲述了TP5框架使用QueryList采集框架爬小说操作。分享给大家供大家参考,具体如下:
最近想写一个小说网站,就去搜资料,搜出来TP5可以使用QueryList采集框架去爬小说,这里我来给大家详解如何用QueryList去爬小说。
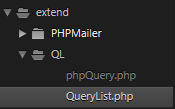
#首先应该下载TP5框架,然后在extend里面建立一个文件夹命名为QL,再去官网下载QueryList,然后把phpQuery.php 和 QueryList.php 两个文件放在QL文件夹下,如图:
##在QueryList.php里面加上命名空间:
namespace QL; require ‘phpQuery.php'; use phpQuery,Exception,ReflectionClass; use Monolog\Logger; use Monolog\Handler\StreamHandler; use Iterator,Countable,ArrayAccess;//使用phpQuuery接口
#准备工作做好了下来开始采集小说(我们这里以https://www.17k.com/这个网站的免费小说为例)
##先找到你要采集的小说的目录页面的url作为采集url
##再在url前面加上 view-source: 查看他的源码,找到包含所有章节url的class属性,写好采集规则,执行语句进行采集
##采集他的章节名和每一章节的url,因为url采集下来没有域名,需要用正则表达式加上https://www.17k.com 然后采用for循环去一个一个采集每一章节的内容
##最后再将采集到的章节名与章节内容存入数据库
直接上代码:
<?php
namespace app\index\Controller;
use think\Controller;
use QL\QueryList;
class Xiaoshuo extends Controller
{
public function index()
{
//采集目标
//$url = 'https://www.17k.com/list/3032846.html?offset=';
$url = 'https://www.17k.com/list/3041226.html?offset=';
//采集规则
$rules = array(
'title'=>array('.ellipsis','text'),//获取书每个章节名
'link'=>array('.Volume a','href','-.folding -copy -a'),//获取每个章节链接
);
//开始采集
$data = QueryList::Query($url,$rules)->data;
//var_dump($data);
//求数组长度
$j = count($data);
if($data)
{
for($i=0;$i<=$j-1;$i++)
{
$values = ['title'=>$data[$i]['title'],'link'=>$data[$i+1]['link']];
$_POST['url']=$data[$i+1]['link'];
if (!preg_match("/^(http|ftp):/", $_POST['url']))//给链接加上域名头
{
$url1 = 'https://www.17k.com'.$_POST['url'];
}
$rules1 = array(
'novel'=>array('.p','text','-li -a'),
);
$data1 = QueryList::Query($url1,$rules1)->data;
//var_dump($data1);
$values1 = ['title'=>$data[$i]['title'],'novel'=>$data1[0]['novel']];//将章节名、内容插入数据库
$data2 = \think\Db::name('novel6')->insert($values1);
}
}
}
}
我们来打印一下他的章节名和章节内容:

 注:1.class属性一定要找对
注:1.class属性一定要找对
2.采集下来 $data 的第一个数组的link不是第一章的url,下一个才是第一章的,所以 d a t a [ data[” role=”presentation” style=”position: relative;”> data[ data[i+1][‘link’] 是他第i章的url
更多关于thinkPHP相关内容感兴趣的读者可查看本站专题